Musicologists and Data Scientists Pull out all the Stops: Defining Renaissance Cadences Systematically
Alexander Morgan (ECORATE, USA), Daniel Russo-Batterham (Melbourne University) and Richard Freedman (Haverford College)
Abstract
Digital tools offer many ways to find musical patterns with machines. But the task of formulating digital-musical systematically, interpreting the results, and refining our methods to yield intelligent insights about musical practice is far more difficult. In this presentation a team of musicologists and data scientists will share our experiences in developing CRIM Intervals, a Python-Pandas toolkit designed to support Citations: The Renaissance Imitation Mass, modeling human expertise in terms that can be used by computers to analyze encoded musical scores, and presenting the results of automated score-reading in forms that scholars can interrogate and refine. This presentation explains how we developed these tools, from understanding the constraints that define a given musical event, to the development of the tools needed to model those constraints, and in turn to the stages of refinement needed to eliminate false negatives and positives.
What is a Cadence?
We will take the seemingly self-evident notion of the cadence as case in point. The English term takes its cue (via French and Italian) from the Latin verb “cadere”: to fall, as our voices do at the end of a sentence. Cadences are thus music moments of closure. But they are also moments of surprise, reversal, and division. They are a crucial part of musical segmentation and thus form building. They are also a key part of the way that words and music are joined together, which in turn connects music with concepts of language, syntax, and narrative. Defining them in analytic terms is thus a high priority.
Of course cadences can be marked in many ways: through melody, rhythm, timbre, tempo, and harmony (as any beginning student of music theory will lament). For those of us interested in music of the years before 1600, counterpoint is key. Already in the earliest years of polyphonic composition musical thinkers found ways to explain contrapuntal cadences as a kind of natural process: two independent voices moving from states of “imperfection” to “perfection” (Cohen 2001). The most typical arrangement involved a cantus (or upper) part moving upwards by step and a tenor (or lower) part moving downward by step. Together they combined to form a major sixth (the “imperfection”) expanding out to an octave (“the perfection”). This clausula vera (“true cadence”) became the basis of much subsequent musical practice, both in its typical form and also through various elaborations. The voice roles of cantus and tenor could be exchanged, thus producing a combination in which an imperfect minor third converges to a perfect unison. Or the essential motion could be prefaced with a carefully prepared dissonance, with a second or seventh preceding the third or sixth (see Figure 1 below).
This kind of intervallic thinking about musical motion about cadences began already in the work of Marchetto of Padua (in the Lucidarium of 1317/18; Marchetto 1985), and continues through authorities like Johannes Tinctoris (in the Liber de arte contrapuncti of 1477; Tinctoris 1961), Giofesso Zarlino (Le istitutioni harmoniche of 1558; Zarlino 1966), Nicolo Vicentino (L’antica musica ridotta alla moderna prattica of 1555; Vicentino 2011), and Joachim Burmeister (Musica poetica of 1606; Burmeister 1993). In their writings we can see how composers and musical thinkers codified the clausula vera not only in two-voice writing, but also in pieces for three, four, or even more voices, now with stereotypical behaviors for altus and bassus parts no less than for the cantus and tenor. Bernhard Meier dubbed these “voice roles” with Latin neologisims (cantizans, altizans, tenorizans, and bassizans) that provide a useful basis for the analysis of the imaginative ways in which composers of the years before 1600 to deploy (and vary) the basic types, through exchange of roles, irregular motions, and other surprising turns (Meier 1988).
As defined in Morgan’s research (Morgan 2019), the Renaissance cadence can be described in four key phases of intervallic discourse en route to a goal tone:
- an acceptable consonant preparation
- a dissonant interval between a sustained note (the “patient”) and another voice that moves into the dissonance (the “agent”)
- an attenuation of this dissonance with the sustained note generally moving down by step to an imperfect interval
- a perfection where both voices move, usually by stepwise contrary motion, to a perfection.
The diversity of types, tones, roles, and modifications heard in Renaissance polyphony provides a perfect testing ground for the digital tools. It is certainly possible for a human analyst to label, track, and account for how cadences work within a single piece. Digital techniques, in contrast, translate musical concepts into routines that can be performed automatically–finding, classifying, and labeling cadences wherever they appear in a single encoded score, or hundreds of them at once.
Digital Detection of Cadences
Our methods are codified in a Python library called CRIM Intervals (Freedman, R., Morgan, A., Gould, F, Russo-Batterham, R, Dang, T. 2020–). Developed as part of Citations: The Renaissance Imitation Mass (Freedman, R., Fiala, D. Russo-Batterham, D., Viglianti, R., Walter, M. 2014–), CRIM Intervals builds on the foundation of Music21 (Cuthbert 2010), and like Music21 works with encoded scores in a variety of formats (MEI, MusicXML, Midi, etc.). It works in local terminal versions, but also is available in a series of user-friendly Jupyter Notebooks (see https://github.com/RichardFreedman/CRIM-Jhub). It is open-sourced, extensible, and (as we explain here) under continuous improvement.
With CRIM Intervals each voice part became a series of notes and rests, and music21 was used to calculate the interval between any two voices at any given moment in the piece.These tabular summaries were represented as a kind of simple ngram (for instance of three successive harmonic intervals, such as 7, 6, 8), and then as contrapuntal modules that represent both harmonic and melodic motion at the same time (see Figure 1a). These are mapped to the music21 “offsets,” which in turn returns the tones involved.

Figure 1a: Typical clausula vera, with suspension, resolution, and perfection, notated as simple harmonic succession between cantizans and tenorizans.
Searching for interval successions like 7, 6, 8, or 3, 2, 1 was a simple first iteration of our tool. It rendered tables of likely cadences (and their tones) in a tiny fraction of the time it would take a human analyst to do so (Figure 1b shows results for one search).
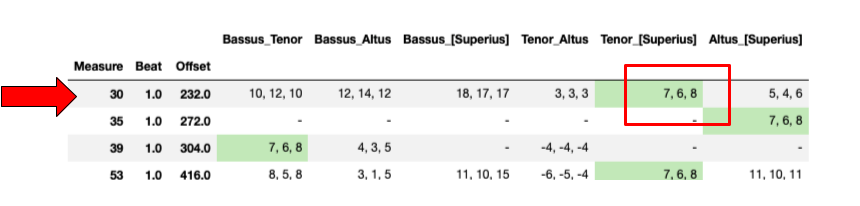
Figure 1b: CRIM Intervals locates harmonic pattern shown in Figure 1a
This was a good start. But we also quickly realized that it was not always correct, and that it sometimes produced false positives among the results, mainly because the harmonic sequences noted above could also be found in non-cadential passages. Thus our next move, building upon the work of SIMSSA team and their VIS analysis framework (Antila and Cumming 2014, and Antila and Morgan 2016), was to understand cadential motion as a modular structure that combined both melodic and harmonic motion. We represented each two-voice contrapuntal module as a succession of harmonic intervals connected by the melodic motions of the voice whose staff is lower in the score (the melodic motion of the upper voice can mostly be inferred given the other information; see Figure 2a).

Figure 2a: Passage from Figure 1, now as with modular notation showing harmonic and melodic motion of two pairs of cadential voice functions: cantizans and tenorizans (in red) and cantizans and (evaded) bassizans (in blue). The schema is labeled by CRIM Intervals as “Authentic Cadence, evaded.”
This slightly more complex type of ngram preserves information about two different kinds of musical motion. Here the results were better than in our first attempt (see Figure 2b).

Figure 2b: CRIM Intervals finds contrapuntal modules shown in Figure 2a
This did much to eliminate false positives, but our tool still failed to catch many irregular cadences in which some voice role dropped out at the last moment, or moved in an unexpected direction. Building upon the lessons learned the HumDrum toolkit (Sapp & Morgan 2018), our method has been to build a “library” of patterns that describe the stereotypical cadential counterpoint formed by various pairs of voices—not only cantizans and tenorizans duets, but also the ways that bassizans or altizans typically combines with one of those voices. These in turn were enriched by scenarios in which the cantizans, tenorizans or bassizans move irregularly, or are suddenly silent. If a given two-voice contrapuntal module maps one pair CVFs (such as cantizans–tenorizans, or cantizans–bassizans) at the moment of a cadence, then conjunctions of such modules allow us to characterize types and sub-types of Renaissance cadences (see Figure 2c).
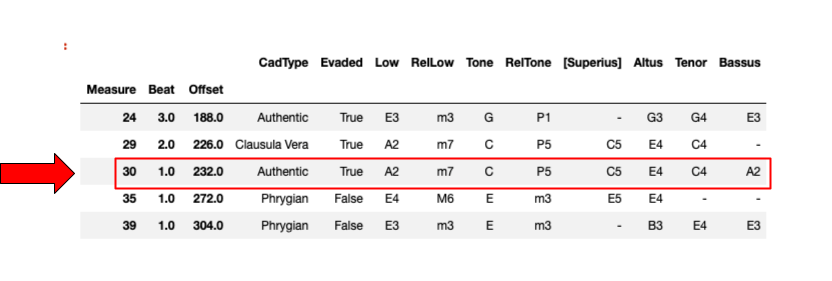
Figure 2c: CRIM Intervals correctly labels the modules shown in Figure 2c as Authentic Cadence, Evaded. Subsequent columns detail pitches in various voices, and information about surrounding cadences
As our contrapuntal module notation is relatively simple to read and edit, we store our module labels and corresponding CVF labels in a table that we add to manually. We currently have 75 labeled modules and the list grows as we improve our detection accuracy, weed out false positives, and support new types of CVF evasion. Table 1 shows our total vocabulary of CVF labels. Lowercase letters are used for CVF evasion. In the interest of uniformity, we kept the same one-character labels as the CVF analysis tool developed by Sapp and Morgan, but added several new categories.
| Label | Cadential Voice Function | Label | Evaded Cadential Voice Function |
| A | Altizans | b | Bassizans evaded by step up |
| B | Bassizans | c | Cantizans evaded by fourth up |
| C | Cantizans | t | Tenorizans evaded by step up |
| L | Leaping Contratenor | u | Bassizans evaded by third down |
| P | Plagal Bassizans | x | Bassizans evaded by dropout |
| T | Tenorizans | y | Cantizans evaded by dropout |
| z | Tenorizans evaded by dropout |
Table 1: Cadential voice functions, both realized and evaded, and their corresponding one-character labels.
To find false positives, we spot-check each “hit” and verify that it is the correct label. False negatives require more work to find, because we have to first analyze a piece “manually”, then cross reference our results with those of the program. The primary source of false positives has been the incorrect identification of chanson idioms (Sigler, A., Wild, J, and Handelman, E. 2015), as the dissonant phases of cadential suspensions. This is because the interval content is the same if we start counting from the dissonant phase of the cadential suspension. To disambiguate these intervallically identical cases, we could either include durational and metric information creating increasingly complex ngrams, or include the preparation phase of the suspensions for these cases. Including durational and metric information would be a larger alteration to our process so we opted to “overfit” our instances of this pattern to include its various preparations too. However, including the preparation of all suspensions would be impractical because of the vast number of acceptable possibilities. The fact that the preparation phase of a suspension is generally not needed for accurate CVF classification (other than in the chanson idiom case mentioned above) is very telling. It shows that the Renaissance cadence is overdetermined in the sense that, while conceptually helpful, durational and metric information are generally not needed to correctly locate and classify CVFs and cadences. Syntactic redundancy underscores the salience of cadences because they can be noticed by a number of distinct domains (harmony, melody, rhythm, duration, text setting, number of voices, etc.). This is similar to how languages also often integrate redundancy such as how intonation and word order can both point to an interrogative statement.
One means of improving accuracy of our tools has been to focus on individual pieces that we know to be difficult cases. A madrigal by the sixteenth-century master Cipriano de Rore, Ite, rime dolenti, ite, sospiri (first published in 1548), is a good case in point (see https://crimproject.org/pieces/CRIM_Model_0025/ for a modern edition). This piece repeatedly frustrates cadential expectations. This is often done by highly irregular melodic motions at the moment of what was expected to be an intervallic perfection. Figure 3 is what caused us to include our “c” label for this type of cantizans evasion.

Figure 3: An evaded cantizans derails intervallic perfection with the lowest voice which has a bassizans CVF. This vitiates the cadential weight of the passage
Another elegant tool Rore uses to deny cadential resolution is to have one or more voices rest at the expected cadential perfection. Figure 4 is a radical instance of this practice–doubtless meant to evoke the sense of ‘escape’ in the text, as expressed in the new line of text ‘Fugg[ir]’, first sung by the cantus at the end of bar 65. In our cadence library, the labels x, y, and z are used for voices that evaporate in this way (see Table 2).

Figure 4: What was set up to be an ordinary authentic cadence is evaded through dropout. The cantizans, tenorizans, and bassizans CVFs are not fully realized since they rest at the moment of the expected perfection. They are given the CVF labels y, z, and x respectively.
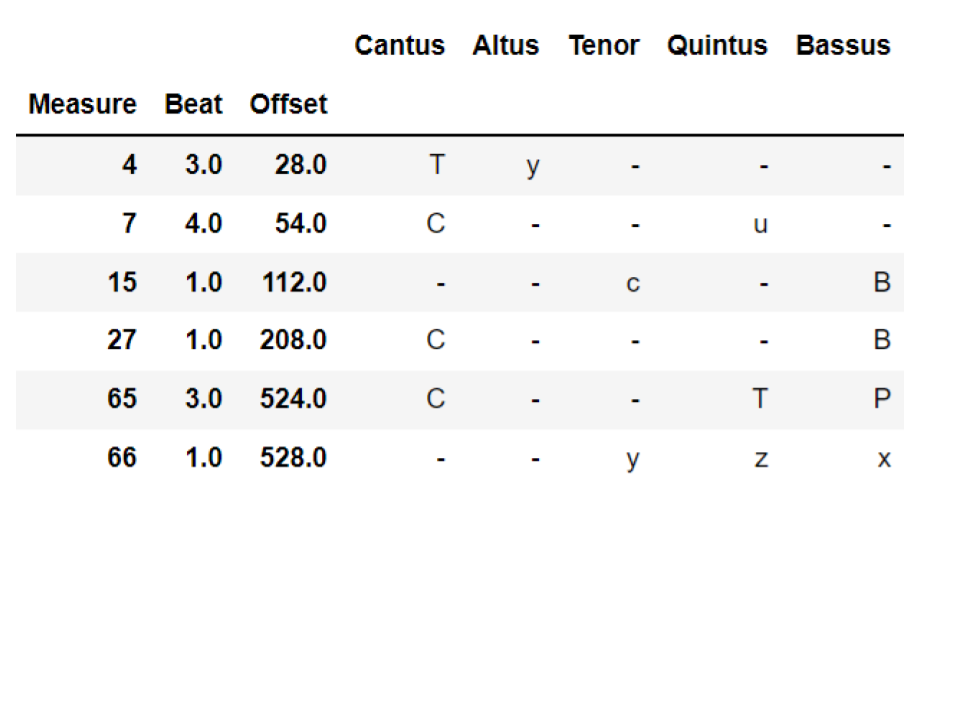
Table 2: CVF analysis of Rore’s Ite, rime dolenti, ite, sospiri
Our cadence labels are based on how our CVFs combine together. We alphabetically sort the CVFs occurring together and associate this with a cadential label in a second table. We currently disregard any tenorizans CVFs if there is a bassizans in that cadence. This simplification belies an interesting theoretical tenet: assuming simple evaded/not evaded categories, if a regular or evaded bassizans is present, any tenorizans will not impact classification. As our contrapuntal modules used diatonic intervals without quality to detect CVFs, here we add the number of chromatic semitones last traversed by each altizans, cantizans, or tenorizans voice to arrive at its CVF label. This allows us to distinguish between authentic and plagal cadences, as well as detect if there appear to be missing ficta. Our two-voice contrapuntal modules combine to produce cadences in two or more voices. We do not have to predefine specific combinations of multi-voice modules because we analyze the combinations of our CVFs, which are abstracted from the modules.
Our program should return a cadential label for each moment in a piece where CVF labels were found. This means that any combination of CVF labels encountered that is not in our table of cadence labels is missing labels. For example, the combination of a bassizans, cantizans, and both a normal tenorizans and an evaded tenorizans was not a combination of CVFs that we associated with a cadence label. When we saw that Figure 5 was unaccounted for in our system, this is what made us realize that, if a bassizans is present, the tenorizans (realized or evaded) does not impact our current binary assessment of evasion.

Figure 5: An evaded tenorizans happens at the same time as a realized tenorizans, both against a cantizans and bassizans in this thicker texture from the Agnus Dei of Palestrina’s Missa Benedicta es
Conclusions
What have we learned from this process, and where will it lead? From the standpoint of musical analysis, our work to date has taught us a good deal about the need for a systematic definition of the Renaissance cadence, which remains deceptively simple. A few key criteria can accurately describe the core harmonic and melodic requirements encountered in these patterns. Yet despite their prominent rhetorical weight, we still have no general theory of how cadences participate in Renaissance form. Accurate and automated cadence analysis is critical to a better understanding of numerous other aspects of Renaissance music, chief among them form.
This in turn will set the stage for the systematic examination of another key means by which Renaissance composers organized their works: what Peter Schubert has called “Presentation Types.” Like cadences, these patterns involve the modular repetition of contrapuntal combinations of voices, often in repeating sets of imitative duos and trios of various kinds. To date, no analyst has systematically defined these schemata. But doing so is a high priority: while cadences occur at the ends of segments, imitative presentation types very frequently mark the beginnings of them. Together they would form a powerful tool by which we could understand how segments of different types succeed each other over the course of a given work, or what works of a given composer or style share with each other at a high level of organization. Such “collocations” (as linguists call the conjunctions or words or patterns in a single utterance) could provide a key measure of how cadences and in turn, pieces, are related by context and usage no less than by their contrapuntal formulation per se (Stefanowitsch and Gries 2003).
Our work with MEI (and other structured data) has been inspired by disparate branches of Data Science more broadly, from our focus on iterative improvement, through to our borrowings from Natural Language Processing. Armed with interactive computing environments like Jupyter, we rapidly test each iteration of this work to identify limitations, and quickly gather feedback from interested stakeholders through applied demonstrations. Data visualization tools allow us to identify at a glance where cadential or other patterns of interest occur; Ngrams and distance metrics (such as Levenshtein distance) provide powerful abstractions when adapted to music; and network theory helps us to present linkages among works based on different types of musical similarity well beyond the explicit relationship between a model and its derivatives. Although data-driven musicology is in its infancy when compared with disciplines such as linguistics, the increasing availability of MEI-encoded scores and the panoply of creative approaches to these bode well for a future where computational tools continue to open new insights into works of this period.
Bibliography
Antila, C. and Cumming, J. 2014. “The VIS Framework: Analyzing Counterpoint in LargeDatasets,” in Proceedings of the International Society for Music Information Retrieval (2014): 71–76.
Antila, C., Morgan A., et al. 2016. VIS Framework (version 3.0.3). McGill University.
Burmeister, J. 1993. Musical Poetics. Translation by B. Rivera. Yale University Press.
Cohen, D. E. 2001. “The Imperfect Seeks Its Perfection: Harmonic Progression, Directed Motion, and Aristotelian Physics.” Music Theory Spectrum 23 (2001): 139-69, http://www.jstor.org/stable/745984
Cuthbert, M. 2010. music21: A toolkit for computer-aided musicology, https://web.mit.edu/music21/
Freedman, R., Fiala, D. Russo-Batterham, D., Viglianti, R., Walter, M. 2014–. Citations: The Renaissance Imitation Mass, https://crimproject.org
Freedman, R., Morgan, A., Gould, F, Russo-Batterham, R, Dang, T., Shostak, O. 2020–. CRIM Intervals, https://github.com/HCDigitalScholarship/intervals and https://github.com/RichardFreedman/CRIM-Jhub
Marchetto, P., & Herlinger, J. W. 1985. The Lucidarium of Marchetto of Padua. Translation by J. W. Herlinger. University of Chicago Press.
Meier, B. 1988. The modes of classical vocal polyphony. Broude Brothers.
Morgan, A. 2017. “Renaissance Interval-Succession Theory: Treatises and Analysis.” PhD diss., McGill University.
Morgan, A. 2019. Renaissance Ternary Suspensions in Theory and Practice, vol. 33. https://www.esm.rochester.edu/integral/33-2019/morgan/)
Sigler, A., Wild, J, and Handelman, E. 2015. “Schematizing the Treatment of Dissonance in 16th-Century Counterpoint.” Proceedings of the 16th International Society for Music Information Retrieval Conference, 645–651. https://doi.org/10.5281/zenodo.1417369
Sapp, C. and Morgan, A. 2017. Dissonant filter for Humlib. https://github.com/craigsapp/humlib/blob/f5766da6dbab46e7b2656c334bd48a4d6c880653/src/tool-dissonant.cpp
Stefanowitsch, A, and Gries, S.T. 2003. “Collostructions: Investigating the interaction of words and constructions.” International Journal of Corpus Linguistics 8: 209–243
Tinctoris, J. 1961. The art of counterpoint: (Liber de arte contrapuncti). Translation by A. Seay. American Institute of Musicology.
Vicentino, N. 2011. Ancient music adapted to modern practice. Translation by R. K. Maniates. Yale University Press.
Zarlino, G. 1966. Istitutioni harmoniche di Gioseffo Zarlino. Gregg.