Words and Music
What Crim Intervals Can Tell Us About the Connection
Jonathan Stroh (Augsburg University)
Introduction
For a human analyst, it is simple to analyze the connection between word and music within a single work of music, no matter the type. On the other hand, analyzing certain properties within a large corpus of pieces is a time-consuming process. CRIM Intervals allows the user to easily extract a huge amount of data from a selected group of pieces to analyze them for certain criteria. It will not magically perform a deep and perfect analysis of the pieces, but it will give an overview of all the characteristics of pieces. CRIM Intervals therefore is a suitable tool to study the connection between music and lyrics in Renaissance Imitation Masses. With the CRIM tools, it is possible to quickly analyze multiple pieces for the same criteria in order to find commonalities as well as differences between them.
The analysis of lyrics and their connection to the music in Renaissance works and earlier times is always a delicate matter, as the exact distribution of text over the melodies is not determined by the composer. Even though there are often no sources showing the distribution of syllables over the notes, in practice, singers always had to decide on which note they wanted to sing which syllable. However, there are a number of rules that the performer used to follow. For modern days it is often up to the editor to decide for a logical distribution of text over the notes. In most cases, doing the simplest solution is the right solution (see Thomas Schmidt-Beste 2013).
This paper will focus on getting a deeper understanding of the connection between lyrics and music using the methods provided by CRIM Intervals. By doing so, we must assume that composers purposefully composed the music to fit the rhythm and melody of the text. Text placement is of course often something surprisingly unclear even in the most carefully prepared sixteenth century sources. Editors often must use their expert judgment in realizing choices that were often left to the discretion (or caprice) performers. Homorhythmic passages, however, are notably immune to such uncertainties, and so we can remain fairly confident that in general our musical texts contain relatively little noise, at least from the standpoint of text-music alignment. What is more, CRIM Intervals can help us discover the kinds of choices that are common and uncommon across the entire corpus.
Below we will therefore explore the use of homorhythm in Renaissance Imitation Masses and their connection to the text. As CRIM Intervals also provides tools to find cadences, which are expected to be found at the end of a phrase as well as Presentation Types that most likely are signs of a new beginning, this essay will also investigate their use within the CRIM corpus as well as there connection to the lyrics.
Homorhythm as Emphasis
At first sight, homorhythm seems to be the easiest way to highlight a text passage in a piece. When all voices sing the same rhythm and the same melody at the same time, the sung text becomes extremely legible, and the passage is highlighted in a polyphonic context. It would therefore only be logical to expect homorhythm to occur in places that are of greater importance within the work as they allow the audience to better understand what is being sung. On the other hand, composers might also want to design precisely these special phrases in a way that makes them stand out musically, not as homorhythms but as polyphonically well-constructed elements of music. Compared to other passages within a work, homorhythm often has a very clear distribution of the text over the notes allowing for a fairly accurate analysis of the connection between the words and the music. In most cases, there is not a lot of editorial freedom in these passages.
In search of Homorhythm
CRIM Interval’s method for finding homorhythm within a piece considers several arguments to filter out the homorhythm instances the user is looking for (see Table 1).
| argument | input | description | default |
| n-gram_length | int | Defines the length at which homorhythms are found. For homorhythmic events >n, it will detect multiple homorhythms. For a homorhythmic n-gram of four piece.homorhythm(n-gram_length=2) it would therefore detect three homorhythms. | 5 |
| full_hr | boolean | For full_hr=True, a dataframe is created that only shows homorhythmic events where all active voices sing the same rhythmic and lyrics n-grams, whereas for full_hr=False, any event is shown where at least two voices have the same rhythm and text. | True |
Table 1. The main arguments of the CRIM Intervals Homorhythm method
As is to be expected with any automatic analysis, the underlying code will yield false positive and false negative results from time to time. Nevertheless, as these do not occur regularly, this still allows us to quickly get an overview of the places where homorhythms are used in a piece.
To detect homorhythm, the method compares both rhythmic and lyric n-grams of all voices for each offset and finds places where at least two voices share the same n-gram. By then comparing the results for both the lyric and the rhythmic n-grams, all homorhythmic events within the piece are located. If full_hr is set to “True”, it then also filters out only those passages where all active voices, i.e. all voices that do not have a pause on that offset, are involved in the homorhythm. The homorhythm method then returns a Pandas dataframe listing all the homorhythmic events in the imported piece, the syllable n-grams each voice sings, and the voices involved in the homorhythm.
Example 1 shows an example of a homorhythmic passage that CRIM Intervals would find when full_hr=True while an example for a homorhythmic passage that not all active voices are involved in is shown in Example 2. Both examples are taken from the Kyrie of Lasso’s “missa super Domine Dominus noster” (https://crimproject.org/masses/CRIM_Mass_0048/).

Example 1 Example for a homorhythmic passage for full_hr=True

Example 2: Example for a homorhythmic passage for full_hr=False
To find out more about when and how often homorhythms occur in the corpus, we can look at the length of the results returned by the homorhythm method. To get a wide array of results, we can look at the results for a range of n-gram lengths as well as looking into both full_hr=True and full_hr=False for all values of n.
For the analysis of homorhythms and their connection to lyrics, focusing on the results for full_hr=True provides a good understanding of how often and when homorhythms are used to highlight text passages. To get an overview of how many homorhythms can be found in the CRIM corpus, we can count the length of the dataframes returned for n-grams of the lengths 2 through 10 (y-axis) and count their occurrence sorted by their respective movement. The following table (Table 2) shows the results:
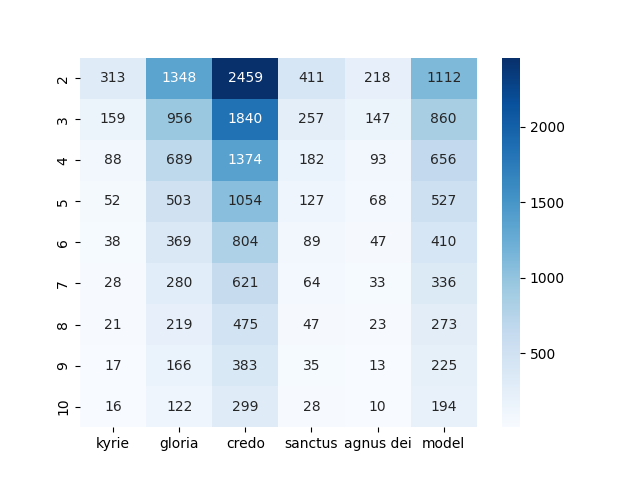
Table 2: Count of homorhythmic passages in the CRIM corpus for 1<n<11 and full_hr=True
As one might expect, most homorhythms are found in the Credo and the Gloria, since these are the longest movements in a Mass. It is also obvious that the number of results decreases, the longer the n-grams become. To be able to compare the density of homorhythmic passages used in a composition, we can divide the number of homorhythms found in all movements by the length of the dataframe returned by the ImportedPiece.notes() method. This gives us the total number of offsets on which at least one voice either has a rest or a note, allowing comparability between the pieces independent from the time signature of a work. (Offsets in the CRIM corpus: Kyrie: 15,409; Gloria: 27,296; Credo: 41,836; Sanctus: 23,377; Agnus Dei: 14,004; Models: 20,239). If we then divide the number of homorhythmic ngrams found by the number of offsets counted, we can compare how densely the homorhythms are used in each movement (Figure 1). On the y-axis different lengths of ngrams are shown while the x-axis shows different movements as well as the value for the models to allow for comparison.
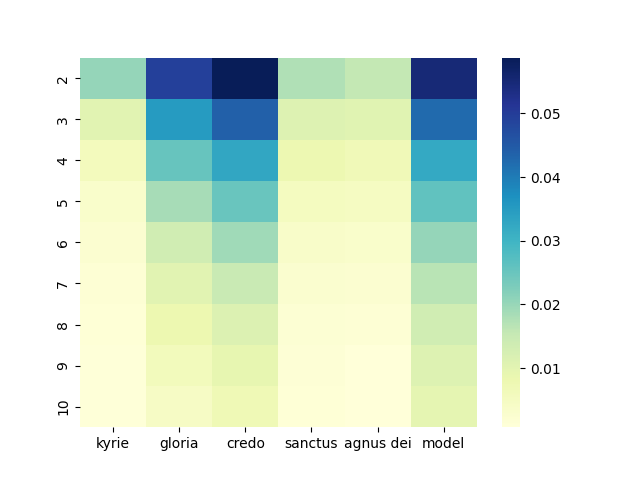
Figure 1: Ratio of homorhythms to offsets in the CRIM corpus
Both the Gloria and the Credo movements seem to have a similar densitiy of homorhythmic events as the models. It is also immediately obvious that both the Gloria and the Credo seem to have a far higher density of homorhythms than any of the other Mass movements, supporting the idea that homorhythms are used to highlight central keywords or short passages of the Christian faith, since these are the two movements that recite key aspects of religious doctrine.
To explore this possibility, it is now time to look at the text that is sung when homorhythms are detected. By applying the homorhythm method to the entire CRIM Mass corpus and counting and sorting the results by their movement and the syllable n-grams, we can find those syllable n-grams that most frequently match homorhythms. CRIM Intervals can automatically identify each work’s movement by comparing a piece’s title to the list of movements:
title = piece.metadata['title']
mvmt = ['kyrie', 'gloria', 'credo', 'sanctus', 'agnus dei']
movement = [m for m in mvmt if m in title.lower()][0]Now that we know the movement of the currently imported piece, we only need to iterate over the results of the homorhythm for both full_hr=True and full_hr=False and for n-grams of different lengths. We can then count all those n-grams that occur homorhythmically.
If we consider only all movements of one type (e.g., only Kyrie), lyrical n-grams for 1<n<11 can be counted as follows:
result ={}
for n in range(2,11):
result[n] = {}
hr = piece.homorhythm(ngram_length=n)
for index, rows in hr.iterrows():
hr_lyr = hr.at[index, hr.at[index, 'hr_voices'][0]]
i = 1
while pd.isna(hr_lyr) and i <= len(hr.at[index, 'hr_voices']):
hr_lyr = hr.at[index, hr.at[index, 'hr_voices'][i]]
i+=1
if pd.isna(hr_lyr):
continue
elif hr_lyr in result[n]:
result[n][hr_lyr] += 1
else:
result[n][hr_lyr] = 1
To find the homorhythmic syllable n-grams for each homorhythm, this algorithm checks for the top voice involved in the homorhythm and saves it to “result” with the value of 1. In the rare case the hr-method detects a voice as part of the homorhythm that has NaN as a lyric n-gram, it will iterate through the voices from the top voice to the lowest voice to find an actual value to add to the dictionary. The algorithm also checks if any of the lyric n-grams has been found before and then just adds 1 to the associated count. We can then repeat the same procedure for all pieces and for both full_hr=True and full_hr=False to count all the lyric n-grams and sort them by movement.
As this produces a huge number of results, most of which have a value of 1, we need to filter them to display a reasonable number in a bar plot. For this, I chose a limit of 80 maximum results to be displayed, but by simply changing the value x this can be used for any maximum number of results to be shown. For the dictionary we created above, the filtering process could look like this:
x = 80
for n in result:
result[n] = current
i = 1
while len(current) > x:
current = {c: current[c] for c in current if current[c] > i}
i += 1This short piece of Code loops through the results while the number of results is higher than the value of x (80 in this case). In each iteration, the results with the lowest count get eliminated from the list leaving a filtered dictionary, i.e. a dictionary containing only the most frequent lyrics n-grams. As we will soon discover, this way of finding, counting and filtering homorhythmic passages in the corpus gives a great overview over their occurrence within the corpus as well as allowing for a deeper understanding how composers use homorhythm to support the sung word.
Homorhythms and Lyrics in CRIM Masses
Coming back to the topic at hand: how are words and music connected in Renaissance Imitation Masses? We can now take a closer look at which syllable n-grams are homorhythmic and whether there are certain text passages that stand out as being composed homorhythmically.
For the Kyrie, Sanctus and Agnus Dei, the expectation of finding text passages that stand out as being composed almost entirely homorhythmically is low. For the Kyrie, the very limited amount of text is reflected in the results when the homorhythmic syllable n-grams are counted. For n-grams of 5, the results look as follows (Figure 2). The same observations can be made for both the Sanctus and Agnus Dei.
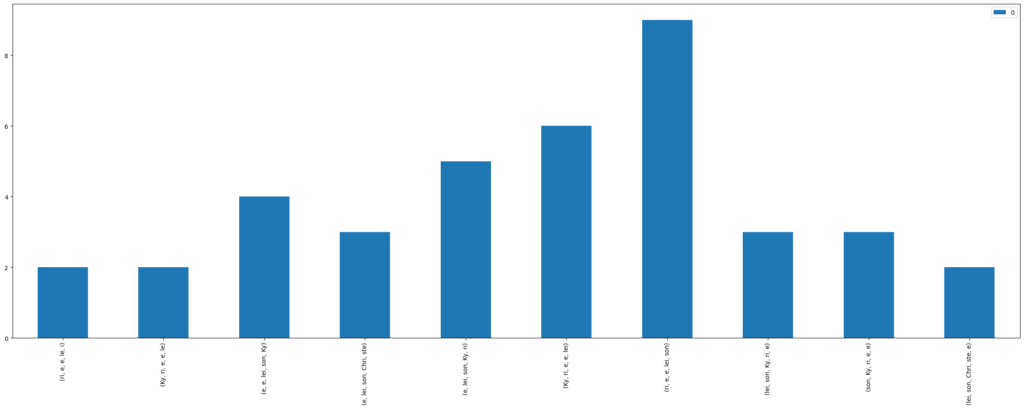
Figure 2: Homorhythmic n-grams of 5 for full_hr=True in all Kyrie movements in the CRIM corpus
It is not surprising that all possible segments of “Kyrie eleison” and “Christe eleison” are found homorhythmically on several occasions. Unfortunately, CRIM Intervals does not recognize that both versions of splitting the syllables in “Kyrie eleison” (either “Ky-ri-e-el-lei-son” or “Ky-rie-e-lei-son”) constitute the same text, meaning that the homorhythm method returns two different n-grams for the same text.
On the other hand, both the Gloria as well as the Credo have a much longer text spread throughout the movement. The text in both of those movements reflects the most substantial and important parts of the christian dogma, so it’s save to assume composers would pay special attention to allow the audience to understand the sung word. Within the movements we would expect the composer to use homorhythm in a way to highlight those key phrases of the dogma. Looking at the result, exactly those expectations seem to be proven right by CRIM Intervals.
As already observed, the density of homorhythm in the Gloria and Credo is considerably higher than in the other movements. This means that many more n-grams are sorted out during the filtering process, resulting in a graph that shows only those n-grams that are composed homorhythmically most often in these movements.
In the Gloria, the phrases that are found to be homorhythmic most often include “in terra pax hominibus”, “benedicimus te” and “adoramus te”, “tu solis dominus”, “tu solis Altissimus” as well as “in gloria dei”. These are all phrases worshiping God, which are the key phrases in the Gloria. The homorhythms seem to be used here to emphasize exactly these phrases, by having all voices sing the text in the same rhythm, which makes it most legible. In a polyphonic context, they stand out even more as this is an abrupt change from what the audience has heard before. However, the most frequently found phrase is “qui tollis peccata”. Since this is also one of the key phrases of the movement and appears twice in the Gloria, it is not surprising that it occurs so often homorhythmically. No less importantly, it becomes apparent that most of these phrases are set in first person plural. This being composed homorhythmically underlines the fact that the words are spoken by a collective, not just one person. In his essay “For whom do the singers sing” Bonnie J. Blackurn makes a similar observation: “It seems entirely appropriate for a choir to sing such prayers collectively, not only on behalf of themselves and the listeners, but for all mankind.” (Bonnie J. Blackburn 1997)
It is interesting to note that for both full_hr=True and full_hr=False, the results for the same n-gram lengths are similar to the relative count of homorhythmic syllable n-grams found. In this case, looking at the results for full_hr=False makes passages that are composed homorhythmically stand out even more than those for full_hr=True, which is probably attributable to the huge difference in the amount of results.
Figures 3 and 4 illustrate a comparison for both variants and n-gram_length=5:
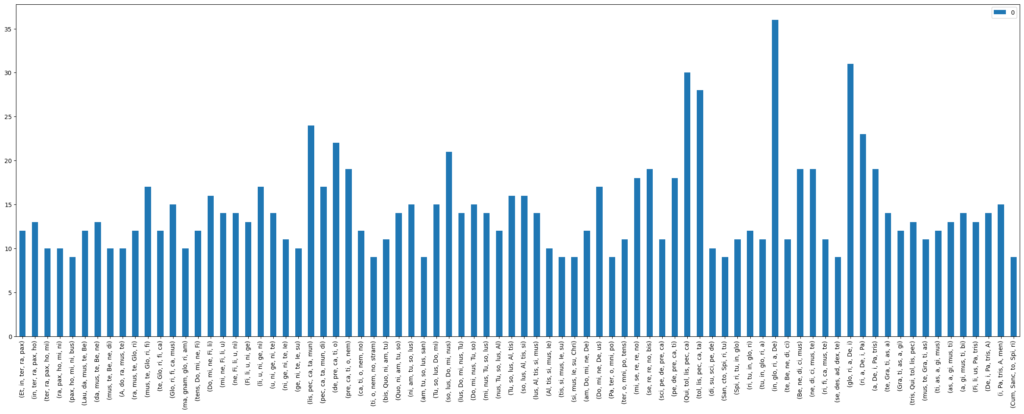
Figure 3: Counts of homorhythmic syllable n-grams for n-gram_length=5 and full_hr=False in all Gloria movements in the CRIM corpus
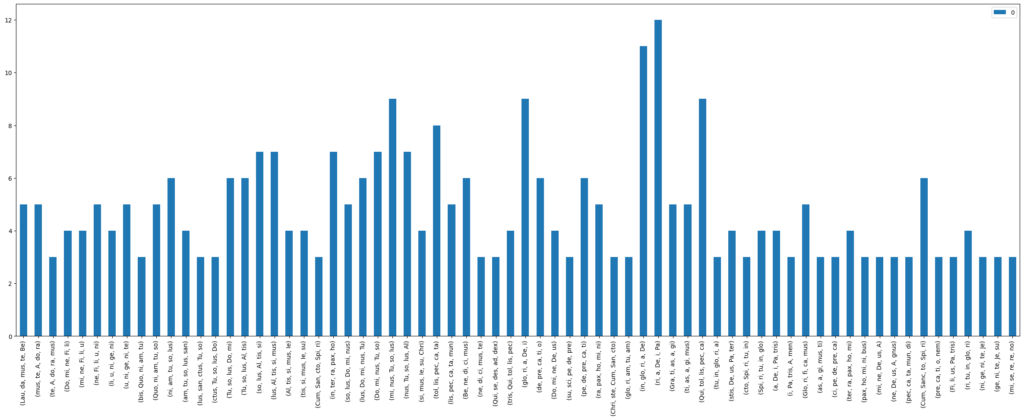
Figure 4: Counts of homorhythmic syllable n-grams for n-gram_length=5 and full_hr=True in all Gloria movements in the CRIM corpus
Similar observations can be made when looking at the Credo. Text passages that are observed to be composed homorhythmically, most often seem to be those passages that have the greatest importance within the movement. Composers also seem to highlight the meaning of words like “unam”/”unum” and “simul” by combining them with homorhythms, literally highlighting the meaning of these words by making all voices sing in unity.
We find words and passages like “patrem omnipotentem”, “spiritu sancto”, “Maria virgine” and “et unam, sanctam, catholicam” to be most often matched with homorhythmic composition (Figure 5 and Figure 6). As those phrases are again key parts of the dogma, it’s not surprising that those phrase are found to be homorhythmic that often.
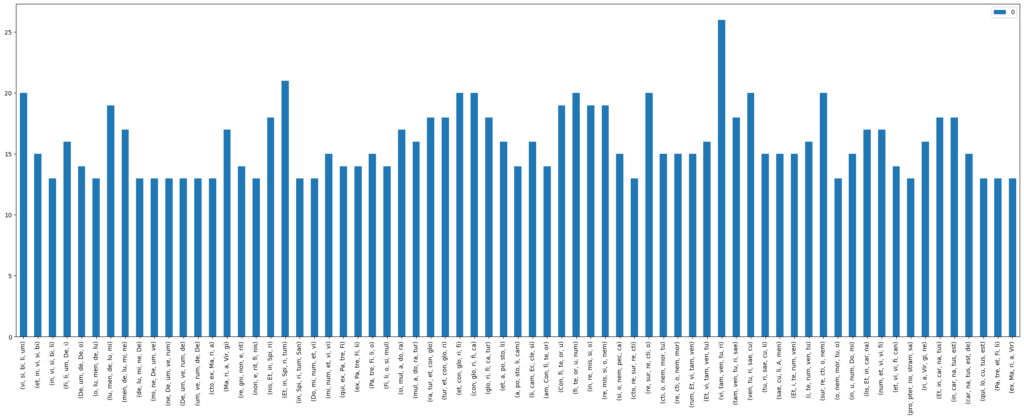
Figure 5: Counts of homorhythmic syllable n-grams for n-gram_length=5 and full_hr=False in all Credo movements in the CRIM corpus
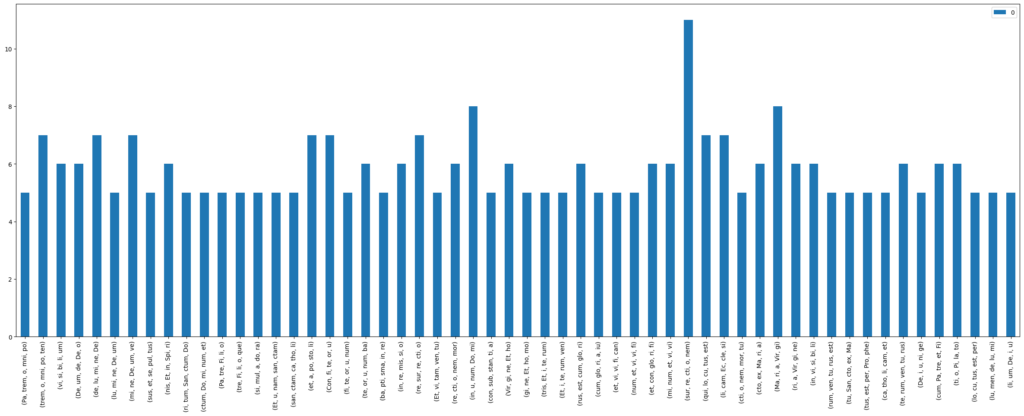
Figure 6: Counts of homorhythmic syllable n-grams for n-gram_length=5 and full_hr=True in all Credo movements in the CRIM corpus
Comparing Different Composers
Using the same methods, it might also be interesting to compare the use of homorhythm by different composers in their Imitation Masses. In the CRIM corpus, there are two composers whose works are best represented: Roland de Lassus and Giovanni Pierluigi da Palestrina. Unfortunately, when applying the methods mentioned above to the works of those two composers in the CRIM corpus, there are no significant results that would distinguish one from the other.
This, however, does not necessarily mean that these composers do not have their own personal style or preferences for the use of homorhythms in their Masses. It is much more likely that the sample group is simply not large enough. For further research on this topic, it would be very interesting to compare different composers in more detail; however, this is beyond the scope of this paper.
The same could be done with compositions created in different eras. Using CRIM Intervals and the methods mentioned above, it would be an easy process to study the use of homorhythms and how they change over time, provided there is a large enough corpus for each era to be studied.
Other Presentation Types and Their Connection to the Lyrics
It is equally interesting to investigate the use of cadences in each movement. Cadences have always marked the end of a musical phrase. If we assume that the music matches the flow of the text, we would expect to find cadences at places where sentences end. As before, investigating the Credo and Gloria movements will be most intriguing because of the amount of text and its importance to the Christian teaching.
To find the text sung where cadences occur, we can create a dataframe of lyrics n-grams (again, I chose an n-gram length of 5, allowing us to identify the places in the text) as well as a dataframe using the cadence method. We then filter the lyrics dataframe for those offsets that are found by the cadence tool and count (as we did with homorhythms) those lyrical n-grams that occur at cadences in a dictionary.
As cadences occur in a polyphonic context, it is not always the case that all active voices sing the same notes. To account for this, a list of all lyrics n-grams that occur at any offset is created and then all of them are counted. If the same lyrics n-gram is sung x times in a single cadence, it will also be counted x times in the result. In Python this process looks as follows:
result = {}
cad = piece.cadences()
lyrics = piece.lyrics()
lyrics = lyrics.applymap(piece._alpha_only)
lyrics_ng = piece.ngrams(df=lyrics, n=5)
syll_set = []
for index, rows in lyrics_ng.iterrows():
syll_no_nan = [x for x in rows if not pd.isna(x)]
syll_set.append(syll_no_nan)
lyrics_ng['syllable set'] = syll_set
for index, rows in cad.iterrows():
if not index in lyrics_ng.index.to_list():
continue
lyrics = lyrics_ng.at[index, 'syllable set']
for l in lyrics:
if l in result:
result[l] += 1
else:
result[l] = 1If we filter these results in the same way we filter the homorhythmic n-grams, we get the most frequent results. When looking at these results (see Figure 7), it is important to note that the syllable n-grams do not only show the syllables that are found in the cadence, but also the following four syllables.
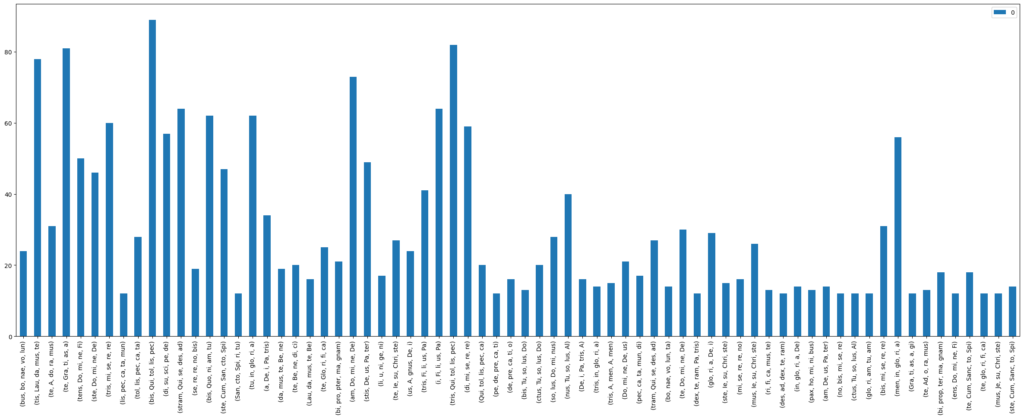
Figure 7: Syllable n-grams of 5 for all cadences in Gloria movements in the CRIM corpus
As expected, we find most of the cadences at places where a new phrase begins in the lyrics. This is especially true for the lines “Domine Deus, Agnus Dei, Filius Patris” and “miserere nobis”, but also for many other phrase-endings (Figure 12).
The same observations can be made for the Credo (see Figure 8). It is not at all surprising to find the single most common result to be a cadence before “et incarnatus est”, marking the end of the first part in the Credo.
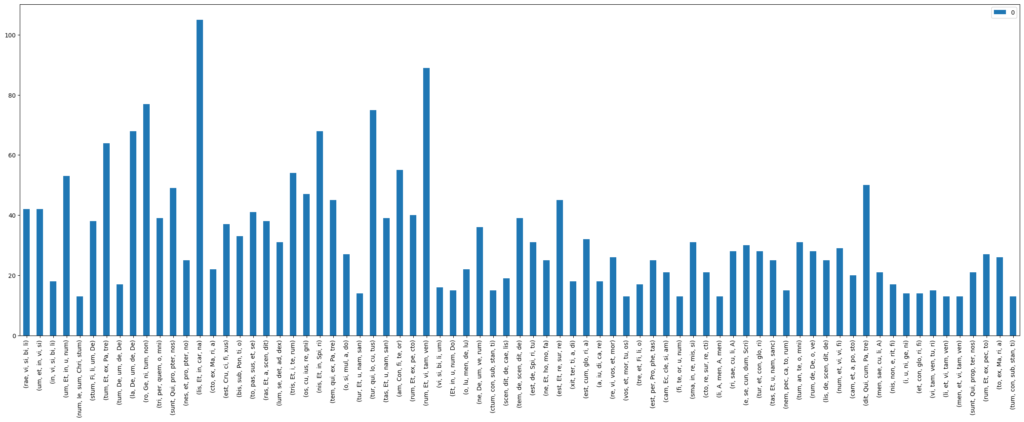
Figure 8: Syllable n-grams of 5 for all cadences in Credo movements of the CRIM corpus
These examples give a very rough overview of the use of cadences in the CRIM corpus and very clearly supports the expectations regarding the use of cadences in music as signs of ending. It would obviously be interesting to also match each syllable n-gram with the cadence type found by CRIM Intervals to learn more about when which type is used most often. This would allow a deeper understanding of the effect of the different types of cadences.
Similar to the investigation of cadences, we can also match all Presentation Types with lyrics n-grams and find the connection between them and the lyrics. In this case, we would expect to find them for new beginnings, most likely after a cadence. It would not be surprising to get very similar results for Presentation Types as for cadences.
The results returned by matching the lyrics n-grams with the Presentation types found are possibly the clearest result of all the methods presented in this paper. To keep the results as accurate as possible and avoid false positive results, the following arguments were used to extract the data presented below:
p_types = piece.presentationTypes(limit_to_entries = True,
body_flex = 0,
head_flex = 1,
include_hidden_types = False,
combine_unisons = False,
melodic_ngram_length = 5)As a Presentation Type consists of multiple entries in different voices of the same soggetto, for each entry in each voice the lyrics n-gram was counted towards the results using this algorithm:
result = {}
for index, rows in p_types.iterrows():
offsets = {}
for a in range(len(p_types.at[index, 'Offsets'])):
offsets[p_types.at[index, 'Offsets'][a]] = p_types.at[index,'Voices'][a]
for o in offsets:
if o not in lyrics_ng.index.to_list():
continue
lyrics = lyrics_ng.at[o, offsets[o]]
if lyrics in result:
result[lyrics] += 1
else:
result[lyrics] = 1As expected, we find Presentation Types most often at the beginning of a new phrase. Most noticeable in the Gloria are phrases like “laudamus te”, “in gloria Dei” and “Filius Patri” (Figure 9). The same observations can be made for the Credo movements, but as the text for these is even longer, the results are far more varied. Surprisingly, “et incarnatus est” is not the most frequently found text that can be matched with a Presentation Type (Figure 10).
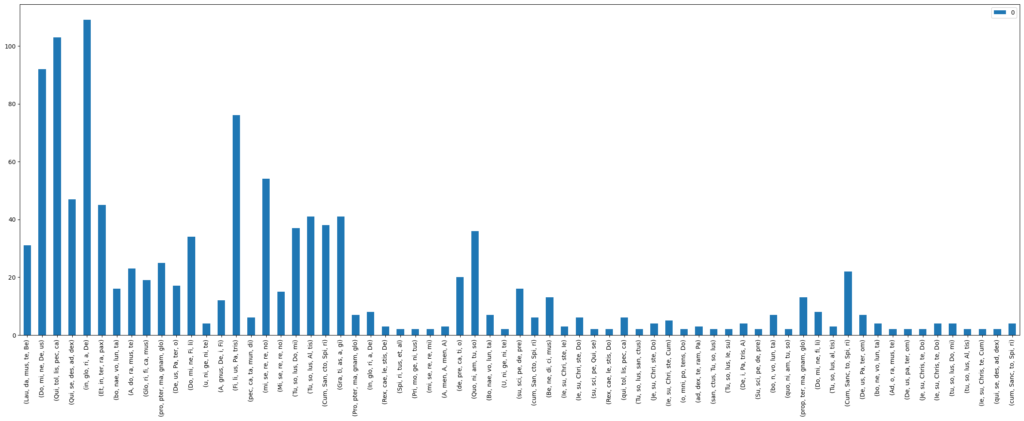
Figure 9: Syllable n-grams at points where CRIM Intervals’ Presentation Types tool finds Fugas, PEns and IDs in Gloria movements in the CRIM corpus
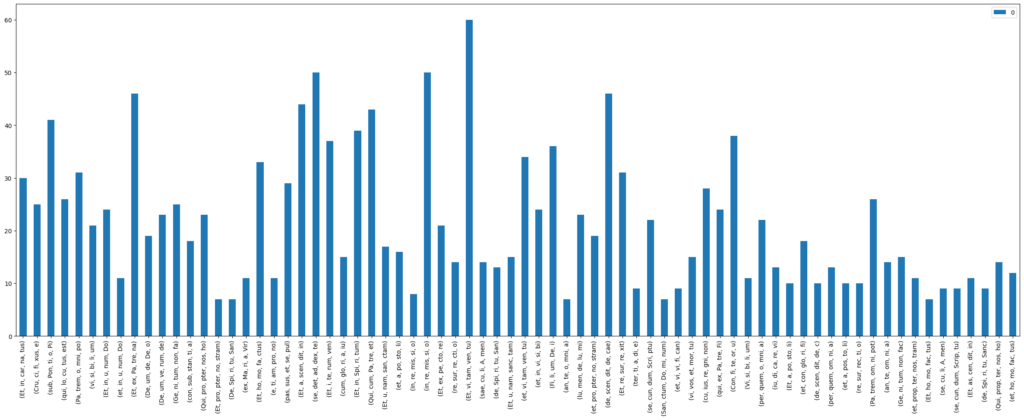
Figure 10: Syllable n-grams at points where CRIM Intervals’ Presentation Types tool finds Fugas, PEns and IDs in Credo movements in the CRIM corpus
Conclusion
CRIM Intervals proves to be a valuable tool to get a general overview of a corpus and its properties. While the use of Jupyter Notebooks might seem counterintuitive at first sight, the ability to easily adapt the code to match the needs of the research question with only basic Python knowledge proves to be a worthwhile feature.
CRIM Intervals is able to easily test empirically expectations on the connection between words and music and allows easy and automatic visualization of the extracted data. Given the experience of analyzing single pieces and the occasional false positive and false negative results, it is to be expected that the data found is not 100% accurate, but this should not have a major impact on the findings. Although a human analyst might be able to analyze musical works more accurately, the vast amount of time one would need to extract so much data from a corpus and count the occurrences manually does not seem worth the improvement in accuracy.
Using the methods presented in this paper, CRIM Intervals should be able to easily compare two or more corpora, either to compare different composers or to investigate the development of text declamation in different eras, given the corpora are large enough to begin with.
References
Blackburn, Bonnie J. 1997. “For Whom Do the Singers Sing?” In Early Music 25 (1997): 593-609.
Cerone, Pietro. 1950. “From El Meleopeo y Maestro” In Source Readings in Music History from Classical Antiquity Through the Romantic Era. edited by Oliver Strunk, 263-269. New York: W.W. Norton and Co.
Thomas Schmidt-Beste. 2013. “Textunterlegung und Textdeklamation.” In Handbuch der Musik der Renaissance. Vol. 2, edited by Michele Calella, 272–295. Laaber: Laaber-Verl.