Conclusions from a Big Batch of Music: Applying CRIM’s Analysis Tools to The 1520s Project
Benjamin Ory (Williams College)
Performing the Corpus Analysis
Our understanding of polyphonic music from the 1520s is spotty at best. Compared with our knowledge of the music of the 1500s and 1510s, it appears that in the following decade we have tumbled off an epistemological cliff. In part, the problem is historiographical. Scholars have often avoided pieces in the musical style that emerges in the 1510s and 1520s in the orbit of the French royal court and on the Italian peninsula. This music often features nearly pervasive sonic saturation—that is, works in as many as five or six independent voices with relatively few rests. Although easy enough to describe in general terms, these pieces are not so easy to analyze. But scholars hoping to control works from the 1520s face a more practical issue, too: more polyphonic music probably survives from during this decade than from any previous one. My digital humanities project, The 1520s Project, aims to meet this challenge by making available more than 250 open-source, high-quality transcriptions (Ory 2023). My project for CRIM uses these scores in conjunction with CRIM’s analytical tools to conduct a corpus analysis with the aim of explaining the use of imitative textures in the early sixteenth century. In doing so, my analysis critically reflects on CRIM’s analytical tools and ontological categories.
The corpus for my project consists of 259 works that date from between the 1510s and 1530s: 247 pieces, including Mass movements, from The 1520s Project, and twelve models and Mass movements provided by CRIM. Note that each Mass section is designated as its own work: thus, there are five works for each Mass ordinary included in the project. The CRIM Masses and models included in this project are the Credo, Sanctus, and Agnus Dei of Willaert’s Missa Mente tota (CRIM Mass 16; the Kyrie and Gloria are already included in The 1520s Project); the Kyrie, Gloria, Credo, and Agnus of Hesdin’s Missa Benedicta es (CRIM Mass 29), Claudin de Sermisy’s Quare fremerunt gentes (CRIM model 10) and Tota pulchra es (CRIM model 11), Nicolas Gombert’s Super flumina Babylonis (CRIM model 29), Lupus Hellinck’s In te Domine speravi (CRIM model 31), and Philippe Verdelot’s Gabriel archangelus (CRIM model 40). See https://crimproject.org/pieces/ for the editions, encodings, and annotations.
To give a sense of scope: my corpus roughly consists of about 250,000 notes or about 26,000 measures of music. It is probably the largest corpus to date to be fed through CRIM’s tools. But although my corpus is substantial in size, it is unlikely to be representative of all the surviving music from the period. For example, at present it has considerable depth in motets from the early sixteenth century, but features relatively few Masses or secular pieces (there are 174 motets, 54 secular works, and 31 Mass movements in all). It is also heavily indexed into a group of young, largely Franco-Flemish, composers who probably begin their careers in the 1510s: Adrian Willaert, Philippe Verdelot (see Julie Cumming’s essay in this collection for more about his music), and Costanzo Festa on the Italian peninsula, and Jean Mouton, Jean Richafort, and Claudin de Sermisy at the French royal court (Figure 1 provides a distribution of works by the best-represented composers in this project). Still, these pieces provide a substantial amount of data that can help quantitatively illuminate music-stylistic features that develop during the early sixteenth century.
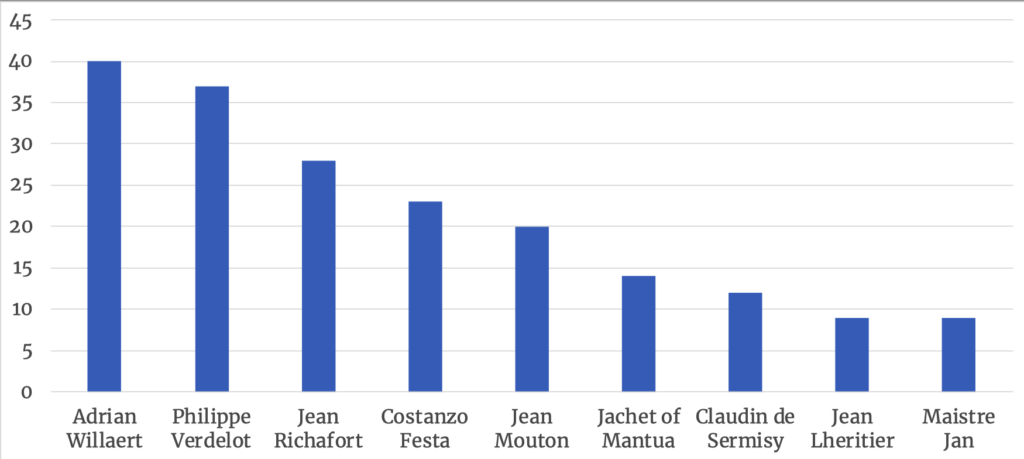
Figure 1. Number of works by the best-represented composers in this project’s corpus
It has long been known that composers in the early-to-mid sixteenth century begin to adopt textures of pervasive (or pervading) imitation, so much so that Howard Mayer Brown once considered characterizing the years 1520–60 as the “age of pervading imitation” (Brown 1976: 187). Although imitation was popularized during the fifteenth century, pervasive imitation—which I take to be a textural phenomenon in which individual imitative gestures are passed successively among the voices of a polyphonic composition, usually with multiple entries in individual voices, thereby saturating the musical space—is primarily a mid sixteenth-century phenomenon (by contrast, on what I would describe as the popularization of imitation, see Cumming and Schubert 2015). Pervasive imitation is central to the aesthetic difficulties that modern listeners have faced when approaching this music. And yet: it is not easy to determine when this texture first took hold. Many, if not most, works at the French royal court and on the Italian peninsula ca. 1520 open with an imitative gambit, but relatively few are driven by imitation following the opening measures. By ca. 1530, pervasive imitation took hold, as exemplified by the motets that appear in the Vallicelliana Partbooks (Rome, Biblioteca Vallicelliana, S1 35–40). This lack of clarity about an important textural shift justifies this project’s focus on imitative types.
Performing the corpus analysis was straightforward. The 1520s Project and CRIM use slightly different, but similar, file standards, and once the durations of my files had been appropriately adjusted, thanks to help from Richard Freedman, they could be uploaded to CRIM’s server in a MusicXML format and fed through the notebooks using the corpus tool. The output was exported as a series of CSV files, which were then analyzed in Microsoft Excel. A handful of music files that are included in The 1520s Project could not easily be formatted for CRIM’s tools; these were excluded from the project.
An initial analysis examined the imitative presentation types in the corpus with an n-gram length of 4 (melodic segments of five notes or greater), no hidden types (each melodic segment can only feature in one imitative module), combined unisons (repeated notes are treated as one note), limit to entries set as true (at least one of the imitative entries must start after a rest, fermata, or section break), a head flex of 1 (enabling alteration of the first note, such as a fourth instead of a fifth, thereby allowing tonal imitation), and without a body flex (following the first note, the melodic segments must be identical). In my project, I will describe this set of parameters as the “base case.” Of the 3358 presentation types recognized in the corpus in the base case analysis, 3066 or 91.3% were fuga, 177 or 5.3% were imitative duos (ID), and 115 or 3.5% were periodic entries (PEn) (see Figure 2).
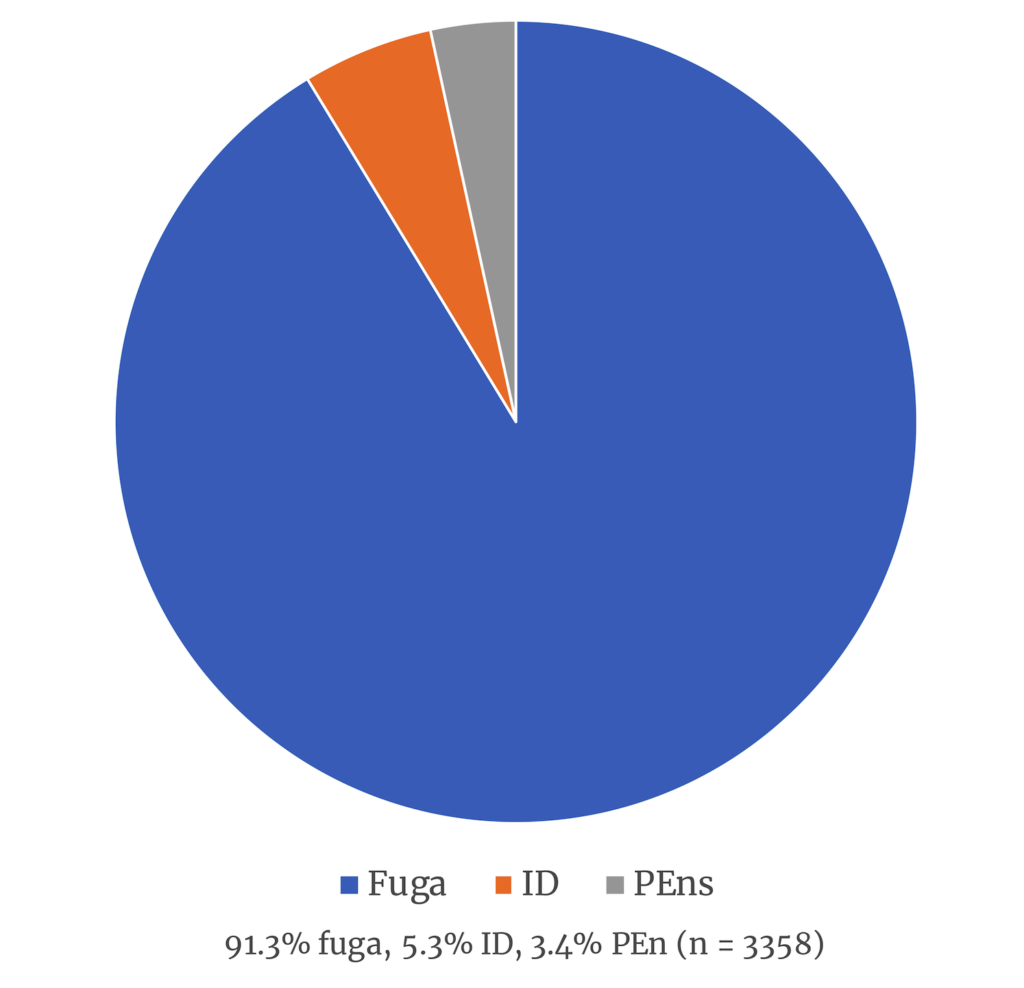
Figure 2. Presentation types under the base case parameters: n-gram length 4, no hidden types, combined unisons, head flex of 1, no body flex
It has been long known that relatively little of this music is constituted through imitative duos, a style that had previously been popularized first by Josquin des Prez in Milan in the 1480s and then in four-voice motets emerging from the French royal court in the 1500s and early 1510s. But for fuga to represent more than 90% of identified imitative types exceeded my expectations.
It does not appear that these results are an anomaly produced by the specific parameters I had selected. Adding flexibility by increasing the head flex or increasing the body flex to 1 or 2 (allowing inexact imitation beyond the opening interval) did not dramatically change the percentages (see Figure 3).
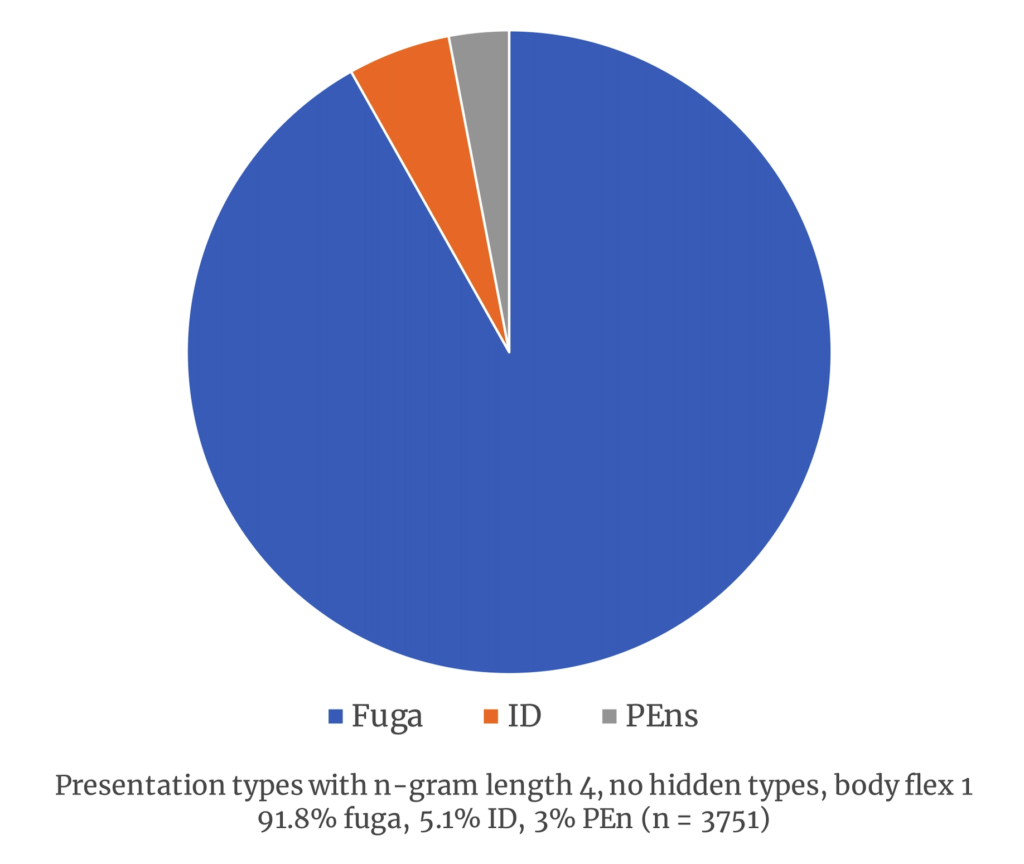
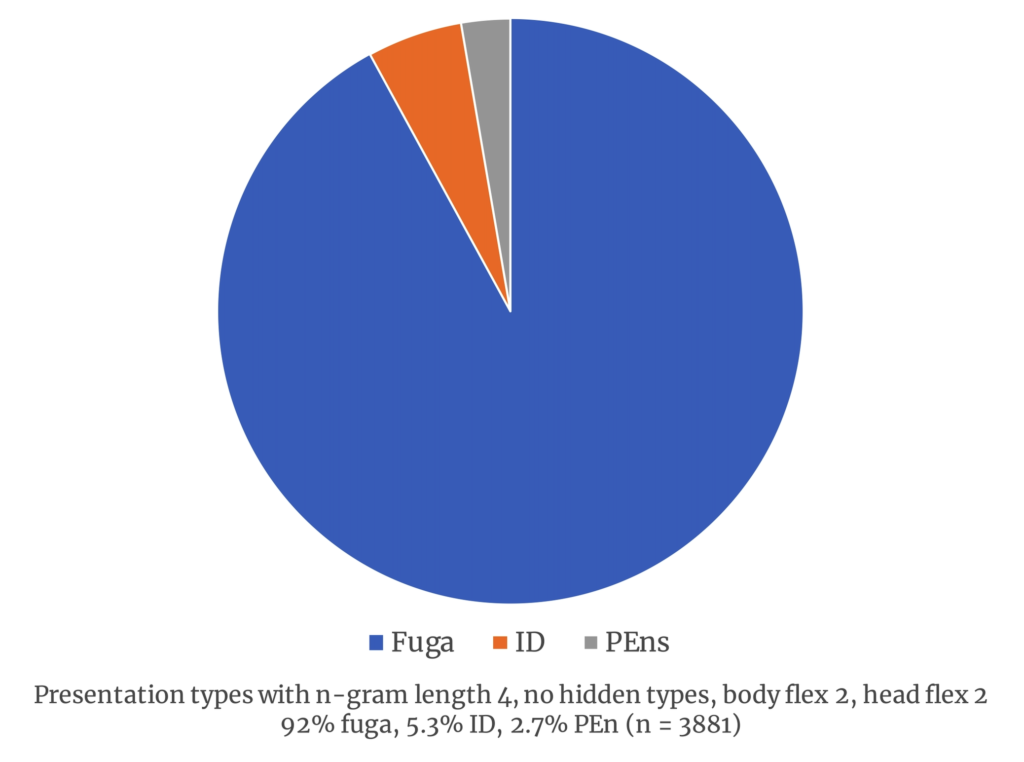
Figure 3. Two sample graphs showing a distribution of presentation types with head and body flexing
Nor did turning off the limit to entries parameter vastly alter the output (Figure 4). And while enabling hidden types created on first blush a more even distribution (45.8% fuga, 34.1% imitative duos, and 20% periodic entries), these results include many overlapping IDs and PEns within larger fuga modules. In other words, the identified modules using hidden types are not necessarily independent. For that reason, the hidden types parameter is better suited to analyses of individual pieces than to surveys of entire corpuses. For all the other analyses, the presentation types tool characterized more than 90% of the identified imitative modules as fuga.
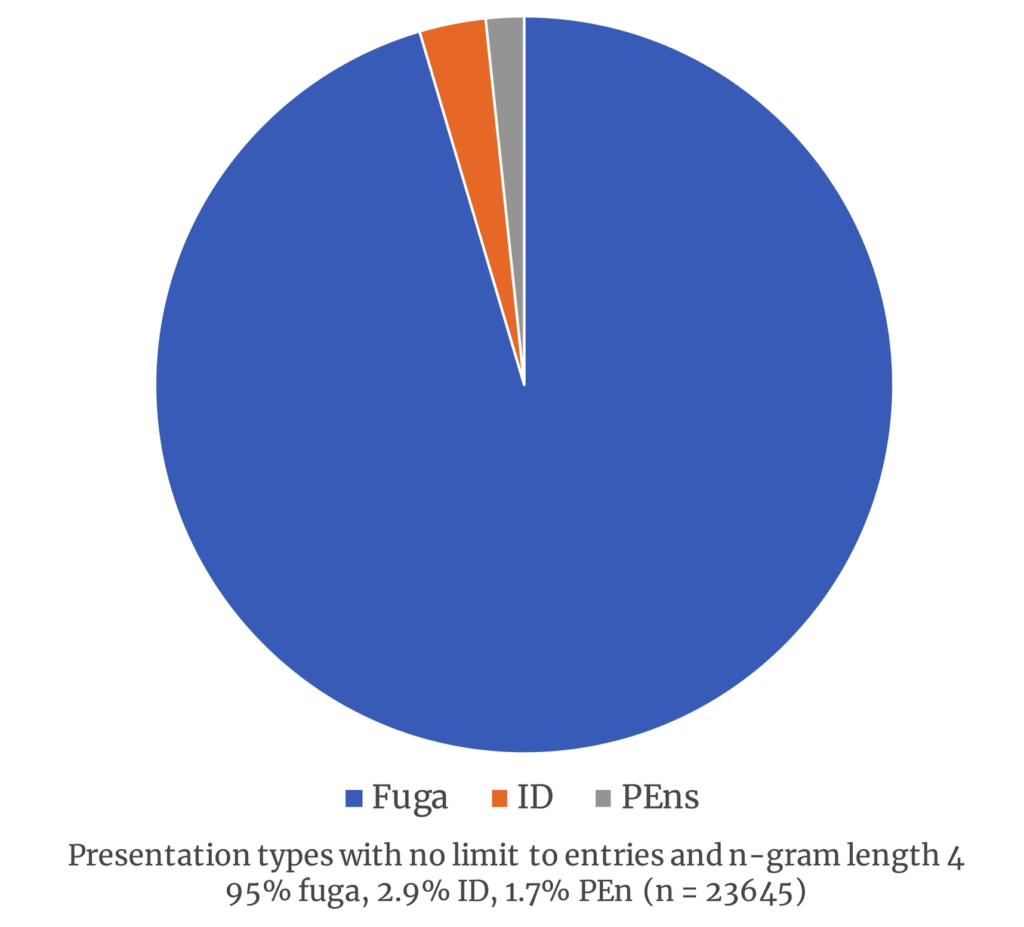
Figure 4. Presentation types with no limit to entries
Some of this consistency probably reflects the ontological requirements of each presentation types category. The minimum number of participating voices for a periodic entry is three; for an imitative duo, four. Neither can exist in just two voices. This means that two-voice modules are recognized as fuga. Indeed, given the base case parameters, more than 50% of all identified presentation types in the output are in two voices (see Figure 5). This is not particularly surprising: two-voice modules should be the most common modules in the corpus and the easiest modules for the presentation types finder to identify. But even when two-voice modules are excluded, fuga still represents an overwhelming percentage of the total presentation types: 81% fuga, 11% imitative duos, 7.5% periodic entries.
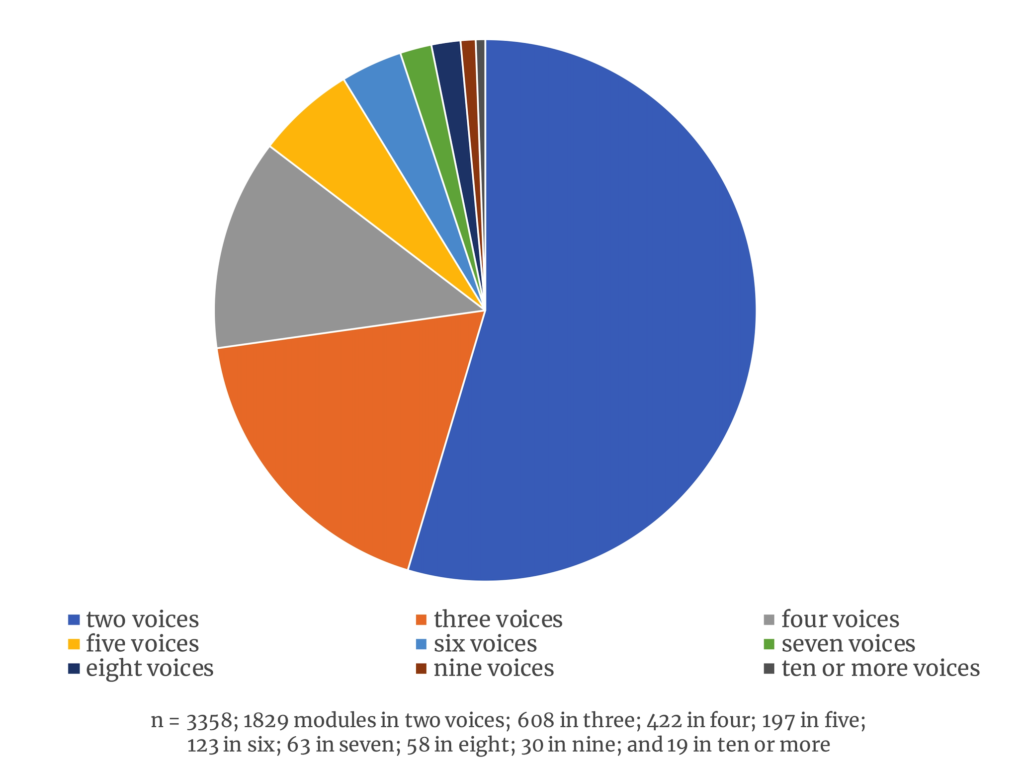
Figure 5. Presentation types identified by number of entrances, or voices, using base case parameters
And these results do not only remain unchanged when different parameters are selected, but they also are relatively consistent between composers. Still, some differences in personal style can be found with respect to imitation. Using the base case parameters, Willaert, for instance, is more likely than his contemporaries to use imitative duos. (Willaert’s music constitutes about 15% of the total notes in the corpus and 16% of the imitative modules identified when using the base case parameters. While he was responsible for only approximately 11% of the total periodic entries identified, his music accounts for 20% of the imitative duos. Nine of the thirty-six imitative duos recognized in music by Willaert can be found in the Missa Mente tota.) But taking a closer look, this number appears to be inflated by my corpus’s inclusion of the double canonic Missa Mente tota, in which the four canonic voices are divided two and two. Each set presents the same melodic material at the same intervallic and durational interval. Since the presentation types finder does not distinguish between double canonic music and free counterpoint, the conditions are set to recognize a series of imitative duos. And yet this description feels misleading: the double canonic structure, not imitative duos, characterizes the texture.
By contrast, while Costanzo Festa is no more likely than his contemporaries to use imitative duos, his music more often features periodic entries. (Festa is responsible for approximately 11% of the total notes in the corpus and 9% of the total imitative modules identified, but 17.4% of the total periodic entries.) To some degree, this tendency stems from Festa’s frequent use of canonic material when composing in more than four voices: with a two-voice canon, to create a three-voice periodic entry only requires the addition of one more imitative entry at the same temporal distance as the existing canonic voices. But other periodic entries, such as in Tribus miraculis, appear even when Festa does not use canonic material as part of a thick texture. All of this makes sense in light of the newfound evidence presented by Philippe Canguilhem that suggests that Festa began composing before either Willaert or Verdelot appear in the historical record (Canguilhem 2022). As an older composer, Festa might have preferred an imitative device prevalent in earlier music.
A third composer, Mouton, appears to be almost twice as likely as the average composer in the corpus to use imitative duos (Mouton’s music represents about 8% of the total notes in corpus, but 15.3% of the total imitative duos). This is also unsurprising—Mouton, who died in 1522, is the oldest composer significantly represented in my corpus. He was also active during the 1510s at the French royal court, an institution at which composers were known to be fond of IDs. But interestingly, this is not true of two of Mouton’s most prominent French royal court successors, Richafort and Sermisy. Neither use IDs more frequently than their contemporaries. (Richafort is responsible for roughly 13% of the notes my corpus: 11.5% of the total modules identified, 11.7% of the fuga modules, 9.6% of the PEns, and 9.6% of the IDs. Sermisy is responsible for roughly 3% of the total notes in my corpus: 3.9% of the total modules identified, 3.9% of the fuga modules, 3.5% of PEns, and 4.5% of IDs.)
Other differences are illuminated when the output is divided chronologically. Using the base case parameters, a similar number of presentation types can be identified when analyzing music that is first transmitted in sources from before 1522 (1560 modules) and after 1522 (1659 modules; modules in music that first appears in sources from 1522 are excluded from this analysis). The biggest difference is that in pieces from before 1522, about 7% are IDs; afterwards, just 3.9% are. In other words, after around 1522, composers in my corpus write about half as many IDs. And the percentage of fuga correspondingly increases (89.3% before 1522; 93.1% after 1522). Composers are now writing more fuga at the expense of other presentation types.
Reflections on the Corpus Analysis
The results of my analyses raise two important questions: first, have the imitative types in the presentation types notebooks been defined effectively? And second, are these imitative types the optimal categories for CRIM to use?
A consideration of the wealth of data produced by the presentation types finder indicates that the definitions for imitative types could be refined. Indeed, the tool currently recognizes more fuga modules than would most human analysts. Take Mouton’s Salva nos, Domine, a six-voice motet that first appears in the Medici Codex (Florence, Biblioteca Medicea-Laurenziana, MS Acquisti e doni 666). Using the base case parameters, the presentation types finder recognizes eight modules in the piece, all of which are labeled as fuga. Seven are two-voice modules, which some scholars might not view as significant enough to label if analyzing the piece by hand; one module is a three-voice fuga module.
Of the two-voice fuga modules, one arises between two entrances in the same voice only (altus, m. 12 and altus, m. 15) and for that reason, should probably be eliminated. And the one three-voice fuga module—which has rightly been recognized by Patrick Macey as part of an example of stretto fuga—could be more precisely labeled (Macey 2017: 274). This module is, in fact, an imitative duo (ex. 1) with flexing, first between the bassus and altus at m. 18 and then between the tenor III and tenor II at mm. 20–21, plus with a fifth entrance in m. 20 in the tenor I. CRIM would not currently recognize this if the required n-gram length was 4, since a rest inserted in the tenor III in m. 22 after four notes disrupts the pattern. But close analysis also points to a more systematic problem in the CRIM results for Salva nos, Domine: the tenor I and tenor II together form a canon at the lower fourth, and this canonic material is interspersed with rests, thereby causing the presentation types finder to pick up four separate examples of two-voice fuga, when in fact, this texture is driven by the preexisting canon, not the individual imitative modules.
If we aim to narrow the results returned by the presentation types finder, this will require more than longer n-grams. While increasing the n-gram length from 4 to 5 reduces the number of results from 3358 to 949, changing this parameter alters the proportions little (fuga, 90.3%; ID, 6.2%; PEn, 3.5%). And restricting the length causes the presentation types finder to ignore imitative entrances in works such as Josquin’s Mente tota. Example 2 shows a three-voice periodic entry (or a fuga with six entrances) that has an n-gram of 4 and which begins with the tenor entrance of “Domino nostro.” Even the n-gram length of 4 omits one entrance in the superius at mm. 25–27 with the text “Iesu Christo,” whose final note descends a fifth, rather than by step. Given the context, this superius entrance is almost surely related. My conclusion: to more effectively define our imitative types, we need to look beyond melodic content, the melodic intervals of imitation, and the temporal distance between entries.

Example 1. Jean Mouton, Salva nos, Domine, mm. 18–24

Example 2. Josquin des Prez, Mente tota, mm. 21–27
Instead, I would like to suggest that better definitions can be achieved through the addition of four further parameters:
- A parameter that examines the rhythmic profile of the melodically identified n-grams. This second step could not only help increase precision, but also narrow results when—as is important for the music of my corpus—limit to entries is turned off and when anticipating enormous numbers of initial results. (As of late 2022, in fact, Freedman and Morgan have implemented a good method for this (“durational ratios”), which model temporal intervals between successive tones in ways analogous to the melodic intervals we already use. The results can in fact be combined melodic intervals to make n-grams that precisely record the time as well as melodic movement of a soggetto, such as “-2_1.0, 3_2.0, -4_0.5”).
- Enable the consideration of imitative entrances in two halves separated by a rest, as is seen in both Josquin’s Mente tota and Willaert’s Verbum bonum. The enormous quantity of results that I suspect would be returned by the presentation types finder could then be narrowed through the use of the rhythmic parameter.
- A consideration of text underlay. Points of imitation often, although certainly not always, share a line or multiple lines of text. Should the texts set by all the voices of the imitative module match, that should give the analyst a higher level of confidence that the results returned are correct. One caveat, however: early sixteenth-century scribes and printers often took a “relaxed” approach to text underlay, with different sources varying substantially. As a result, a significant amount of text underlay in modern scores is the result of editorial decisions by modern editors, and it must be acknowledged that this risks circular reasoning.
- And—potentially most significantly for my repertoire—a parameter enabling the exclusion of strictly canonic voices from consideration for certain presentation types. It should be possible to systematically exclude all two-voice fuga modules between the two canonic voices of a five- or six-voice composition. It is probably also beneficial to systematically group double canonic pieces, such as Willaert’s Missa Mente tota. (Freedman suggests that this could be done via routines in Pandas that could remove voices in which the soggetti and time differences between them are always the same.)
While each of these improvements would incrementally improve the presentation types finder, it is harder to determine whether the current presentation types are optimal. A number of musical types used by CRIM originated from Peter Schubert’s article on Giovanni Pierluigi da Palestrina’s first book of four-voice motets. These types were adopted enthusiastically without all members of the community having arrived at a consensus. Some of Schubert’s musical types are logical and have a historical grounding. For example, Schubert has noted the theoretical underpinning of imitative duos: three separate sixteenth-century theorists note that four-voice music can be composed through repetitions of pairs of duos (Schubert 2002: 519–23; Schubert 2007: 485).
But I am not aware of contemporary theorists—Schubert does not mention any in his article, nor to be fair, was his aim necessarily to find them—who without a doubt discuss periodic entries (Francisco de Montanos and Pietro Cerone both describe “entrada con un passo,” as mentioned by Schubert 2007: 498n24, although as Schubert notes, it is hard to be certain if this denotes a periodic entry). Certainly, these modules can be identified in Palestrina’s music and similarly, in music from Ottaviano Petrucci’s first five motet prints (Cumming 2012: 96). But if the tools developed by CRIM aim to be relevant for music ranging from the late fifteenth century through the end of the sixteenth century, it must be acknowledged how rare periodic entries are in works that appear chronologically in between Petrucci’s prints and Palestrina (just around 3% of the currently recognized imitative entries in my corpus). It is also not apparent why this category should be privileged, especially when considering that PEns are essentially a subset of fuga distinguished only by a consistent time interval between entries.
And the category of fuga—itself a modern label coined by John Milsom to replace the terms imitation and pervading imitation—does not appear to offer sufficient precision (Milsom 2005: 294). At present, CRIM uses fuga to describe all imitation not organized in duos and whose entrances are not at a consistent time interval. And again, my definition of pervasive imitation points to a textural phenomenon that creates density through the use of overlapping, unyielding motivic entries. While individual points of entry regarded by CRIM as fuga are necessary prerequisites for pervasive imitation, a single point of entry does not create pervasive imitation on its own.
CRIM would benefit by surveying a wide variety of fifteenth- and sixteenth-century music and then developing categories and tools based on these findings. While all algorithms incorporate human assumptions, at present, the danger is that CRIM’s ontological categories, having been trained on a small number of unrepresentative pieces, most notably Josquin’s Ave Maria … virgo serena, overfit to the imitative modules in these specific works (see Bokulich 2020 for the modern historiographical Rorschach test of Josquin’s motet). The risk is that when applied, our analytical categories say more about ourselves as modern analysts than they do about the sixteenth-century music that we are analyzing. And for the music of The 1520s Project, if the imitative categories are less relevant, we risk establishing an analytical paradigm that once again marginalizes the works and composers of this period.
My corpus analysis bears witness to the powerful tool that CRIM has developed with the presentation types finder. Thanks to the hard work of Freedman and the editorial and technical team, there is no doubt that CRIM has been highly successful, offering a blueprint for computer-based analyses of Renaissance music. By stretching CRIM’s analytical tools and raising new questions, my project points to ways that the presentation types finder and our understanding of imitation as early music scholars can be refined, expanded, and made more precise.
Bibliography:
Bokulich, C. 2020. “Remaking a Motet: How and When Josquin’s Ave Maria … virgo serena Became The Ave Maria.” Early Music History 39: 1–73, https://doi.org/10.1017/S0261127920000017
Brown, H. M. 1976. Music in the Renaissance. Prentice-Hall.
Canguilhem, P. 2022. “‘Le basse sono bone per imparare a cantar a contraponto’: Costanzo Festa’s counterpoints on La Spagna in the Light of a Newly Rediscovered Source.” Paper presented at the annual Medieval and Renaissance Music Conference, Uppsala, 4-7 July 2022.
Cumming, J. E. 2012. “Text Setting and Imitative Technique in Petrucci’s First Five Motet Prints.” The Motet around 1500: On the Relationship of Imitation and Text Treatment?. Thomas Schmidt-Beste, ed. Brepols. 83–110.
Cumming, J. E., & Schubert, P. 2015. “The Origins of Pervasive Imitation.” The Cambridge History of Fifteenth-Century Music. Jessie Rodin and Anna Maria Busse Berger, ed. Cambridge University Press, 200–28.
Macey, P. 2018. “Jean Mouton: Canon, Cantus Firmus, and the ‘Combinative Impulse’ in Motets for Five Voices.” Journal of the Alamire Foundation 10: 237–90, https://doi.org/10.1484/J.JAF.5.116520
Milsom, J. 2005. “Crecquillon, Clemens, and four-voice fuga.” Beyond Contemporary Fame: Reassessing the Art of Clemens non Papa and Thomas Crecquillon. Eric Jas, ed. Brepols. 293–345.
Ory, B. 2023. The 1520s Project, http://1520s-Project.org.
Schubert, P. 2002. “Counterpoint Pedagogy in the Renaissance.” The Cambridge History of Western Music Theory. Thomas Christensen, ed. Cambridge University Press, 503–33.
Schubert, P. N. 2007. “Hidden Forms in Palestrina’s First Book of Four-Voice Motets.” Journal of the American Musicological Society 60: 483–556, https://www.jstor.org/stable/10.1525/
jams.2007.60.3.483