CRIM and the Ontology for Analytic Claims in Music (OMAC)
Emilio Sanfilippo (ISTC-CNR Laboratory for Applied Ontology) and Richard Freedman (Haverford College)
Ontologies -Then and Now
Philosophical ontology is traditionally conceived as the study of the most general kinds or categories into which entities in the world divide (Berto and Plebani 2015). A well-known ontological system of this sort is the Porphyrian tree (by the philosopher Porphyry), where different categories are shaped in a tree-structure from the most general to the most specific ones. For example, in the representation of the Porphyrian tree in Fig. 1, Substance is the most general category, which further specializes in Body (an extended substance) and other classes down to Human, whereas Plato is a particular (instance of) human.
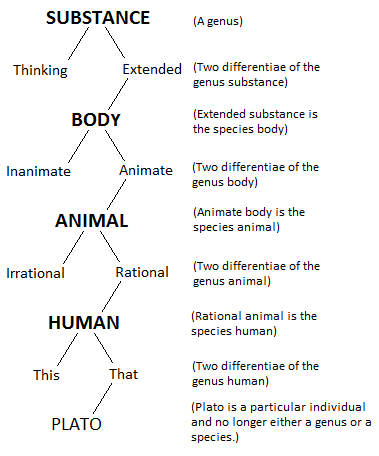
Figure 1 – A representation of the Porphyrian tree (from Wikipedia – https://en.wikipedia.org/wiki/Porphyrian_tree)
An ontological system so conceived is a sort of inventory of the kinds of things that (are assumed to) exist, an inventory of what there is. Such ways of thinking might at first seem to be very far indeed from the world of sixteenth-century counterpoint. But in fact they were quite familiar to Renaissance thinkers. First transmitted from Classical antiquity to the great scholastic tradition inaugurated by the sixth-century Roman senator and polymath Anicius Manlius Severinus Boethius (d. 524), this hierarchical way of organizing entities was extremely common in philosophical writings of the next thousand years.
Such theoretical debates on ontology have led to a plethora of different, often contrasting, positions and schools of thought, and the debate is still alive today. What is perhaps surprising to those with a philosophical background is that nowadays there is a hot debate on ontological matters. Interestingly, many of these are focused on the challenge of developing ontologies for computer science research and applications (Staab and Studer 2010). In the ’90s, computer scientists dealing with artificial intelligence, software engineering, and database systems realized that philosophical ontology could be indeed functional for their purposes. Consider, for instance, a common computer science project where one needs to develop a model for an application, e.g., a database schema to organize the data of the statues in a museum. A computer scientist will need to draw subtle distinctions between different types of statues, providing information about their production context (artists and epochs), characteristics (dimension, material, color, shape, etc), and all sorts of information that is relevant from a cultural heritage perspective (restoration, trading, cultural value, etc). At the end of the day, the computer scientist will produce an “inventory of statues”, namely an ontology describing what statues are. The discipline of Applied Ontology is the interdisciplinary field–at the intersection between philosophy, computer science, logic, and linguistics–devoted to the study of conceptual, formal, and application aspects for the development and use of ontologies (Guarino and Musen 2015).
What Do Ontologies Look Like?
An ontology (in the computer science sense) is a model representing the kinds of things we talk about in an application domain. In an alternative but equivalent view, an ontology represents a vocabulary of terms describing the nature and structure of a domain (Guarino et al. 2010). In the case of bio-medicine, for instance, ontologies represent things like organisms, organs, cells, diseases, etc; in mechanical engineering, they represent machines, design specifications, products, materials, entire factories, production processes, etc. In music, they represent all sorts of things concerning the musical world, e.g., composers, artists, scores, concerts, performers, musical instruments, and (as we show here) critical claims about any of these things.
Ontologies can be used in a variety of ways, although the range of applications varies depending on various factors like the type of ontology and its degree of formal representation. Leaving aside these considerations, ontologies are used to facilitate mutual understanding between people, between people and machines, and machines among themselves. In more concrete terms, ontologies are used to organize, store, and access data although the most common application scenario is likely data integration, e.g., when datasets from different organizations are merged in a meaningful manner. Some ontology-based applications also take advantage of automated reasoning, that is, when a computer system can infer new information from asserted data through an ontology (see Keet 2018).
Ontologies developed with the languages and technologies of the Semantic Web (Hitzler et al. 2009) lay at the ground of initiatives like the Linked Data (https://en.wikipedia.org/wiki/Linked_data) or the FAIR principles (F for findable, A for accessible, I for interoperable, and R for reusable; Wilkinson et al. 2016). The core ideas are to represent data in the same formal language, to make as far as possible explicit its intended semantics (what the data mean), and to make them available through Web resources to facilitate their sharing and possibly integration. For instance, if an organization produces data about musical compositions, and another organization produces data about performances, one could compare the two datasets to possibly produce a larger dataset, e.g., to know where and when a composition was played.
Does all this matter for CRIM?
We said that ontologies come in different forms and for different purposes. CRIM’s (relational) database schema is an ontology (see Giunchiglia and Zaihrayeu 2007), namely, a model classifying CRIM’s data in a precise manner according to the understanding of music shared by the scholars involved in the project. For example, it distinguishes musical compositions from other things like persons, observations, or musical relationships. In addition, it distinguishes musical compositions from their representation (one work can have an original source in choirbook or partbook format, or a score with all parts aligned, or even an encoded version in the MEI XML standard) , as well as compositions of different genres (e.g., masses, chansons, motets, etc.). To make things still more complex, CRIM includes thousands of analytic observations about the works found here, themselves based on a vocabulary of musical schema that reveal connections between works.
Within CRIM itself, these data (and the logic that connects them) is very useful for participants in the project. But a Semantic Web ontology – like the one we present in the following sections – can make CRIM data FAIR. First, it can be used to expose (portions of) CRIM’s data to the Web in such a way that scholars can access and reuse them for their own scholarly purposes. Second, it can help in integrating CRIM’s data with overlapping data produced by other parties, e.g., data of Renaissance music produced by other research centers world-wide. Third, because of its formal structure and by exploiting reasoning mechanisms, it can help to infer information that is only implicitly asserted in the data.
Insights on Ontologies and the Semantic Web
The Ontology for Analytic Claims in Music (OMAC; https://github.com/HCDigitalScholarship/OMAC/) is an attempt to make a portion of CRIM’s data available for further processing in the scope of Semantic Web technologies and platforms. Before we dive into the workings of OMAC, however, we first need to spend some words on both ontologies and the Semantic Web, which are useful bits of information to understand how OMAC works.
There exist different kinds of ontologies depending on multiple dimensions, e.g., level of abstraction or degree of formal representation. A (relational) database schema is an example of ontology represented in the specific formal languages for database design. As said, common languages for ontology development are the W3C standards for the Semantic Web (see below for some intuitions; Hitzler et al. 2009). However, some research communities prefer using languages which are more expressive (in terms of what can be represented) and less computable, e.g., because they primarily seek conceptual clarity rather than computational processing (and Semantic Web languages are very limited in terms of what one can express). This should not be surprising since ontologies may not be even specified through formal languages. For instance, they are sometimes used as reference vocabularies within members’ organizations, in which case (a structured form of) natural language is sufficient.
Independently on the degree of formal representation, the main ingredients of ontologies are classes, relations, and “restrictions”.
Classes. Intuitively, Paris, Beethoven, and the concert of Beethoven’s Ninth at the Opera in Paris on February 22, 2023 are all (non-repeatable) individuals. On the other hand, City, Person, and Concert are examples of classes. We said above that an ontology represents what kinds of entities exist in an application domain. This can be made now more precise: an ontology represents classes of individuals in a domain.
Relations. Relations are used to link the classes of an ontology, therefore the classes’ members. Ontologies commonly cover different kinds of domain-specific relations; e.g., the one holding between a composer and their compositions, a person and their birth date or birth place, a concert to the ensemble that performed in it, etc. A most general and fundamental relationship used in all ontologies is the so-called IS-A relation, which allows structuring ontologies in the form of taxonomies of classes. For instance, Composer IS-A Person means that all composers are persons, too; Sculpture IS-A Artwork means that all sculptures are artworks, too, etc. The figure below (Fig. 2) shows a simple taxonomy of classes in the UML Class diagram notation; it represents Composer, Musicologist, and Performer as direct subclasses of Person, and Pianist, Violinist, and Cellist as direct subclasses of Performer.
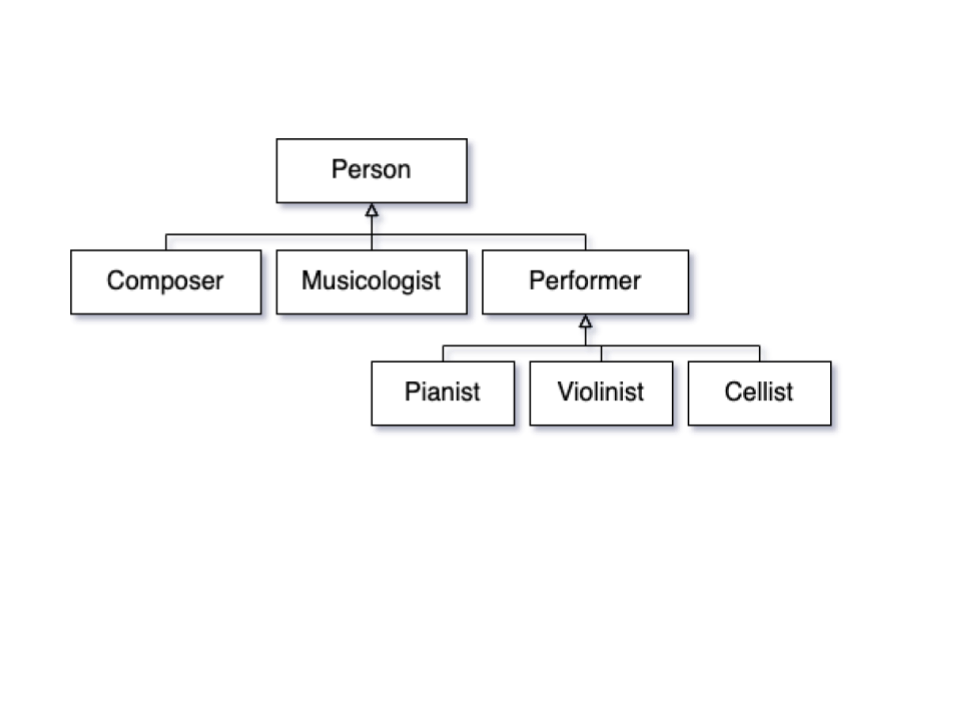
Figure 2 – Example of simple taxonomy (in the UML Class Diagram notation)
Restrictions. It is common in ontologies to use “restrictions” like formal axioms, i.e., statements that are always true, to spell out the intended meaning of both classes and relations. For instance, we may wish to explicitly declare that the class Composer captures those persons who are the authors of at least one musical composition, or that instances of Movement are authorial parts of musical works. The use of axioms depends on the modeling language one uses, and not all languages have the same capabilities in terms of the restrictions which they allow to express.
Moving now to the Semantic Web, its vision has been introduced by Tim-Berners Lee (the creator of the Web), James Hendler, and Ora Lassila in an article published in the Scientific American in 2001 (Berners-Lee et al. 2001). According to its founders, the Semantic Web is not an alternative to the Web; rather, it consists in the enhancement of the Web with services and applications based on an explicit representation of data’s semantics in such a way to allow machines to intelligently process data. Apart from this view, the Semantic Web’s vision has led to the development of formal languages and technologies that became the standards for implementing ontologies in computational settings. Hence, Semantic Web methods are nowadays used as key enablers for data sharing, discovery, integration, and reuse. Said that, it is important to stress once again that the field of applied ontology, as the systematic study of ontologies from a methodological, conceptual, formal, and technological perspective, is broader than Semantic Web efforts.
There are three main languages for the Semantic Web: RDF (https://www.w3.org/TR/rdf11-primer/), RDFS (https://www.w3.org/TR/rdf-schema/) and OWL (https://www.w3.org/TR/owl2-primer/). RDF is the language for data, whereas RDFS and OWL are the ontology languages (see Hitzler et al. 2012 for further reading). A Semantic Web model is a (directed) graph which is represented via a simple RDF triple of three elements: a subject, a predicate, and an object (in this order). For instance,
Beethoven composer_of NinthSympony
is a (informally written) triple having Beethoven as subject, composer_of as relation, and NinthSymphony as object; the triple conveys the intuitive meaning that Beehoven is the composer of the Symphony No. 9. The triple corresponds to the RDF graph in Fig. 3 (where the arc for the relation composer_of is directed in the sense of pointing from Beethoven to the NinthSymphony).
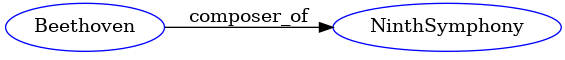
Figure 3 – Example of RDF triple representing Beehoven as the composer of the NinthSymphony
By representing multiple triples, possibly with different interrelated subjects and objects, one obtains RDF graphs of different size and complexity. For instance, the RDF graph in Fig. 4 extends the previous one with additional (simple) information on both Beethoven and the Ninth.
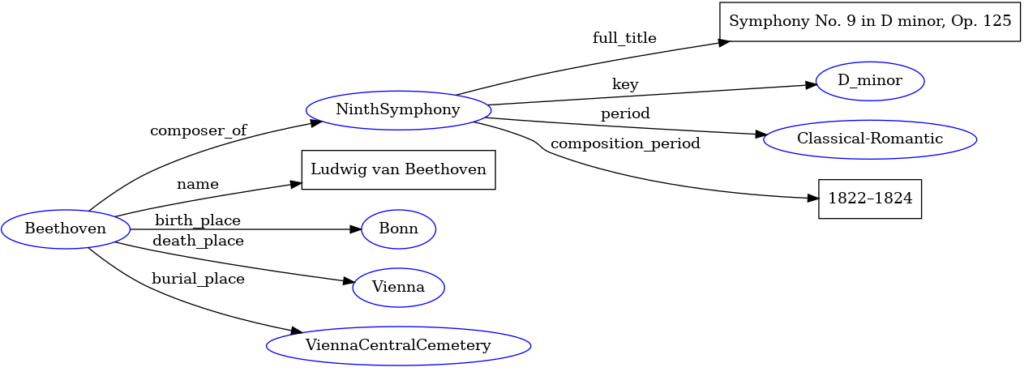
Figure 4 – Example of RDF triple (it extends the graph in Fig. 3)
A thing to know about the Semantic Web is that, apart from data values like strings or integers, and the so-called blank nodes, each element in a RDF triple (graph) is identified by a unique identifier in the form of a Uniform Resource Identifier (URI). Recall that URIs are generalizations of Web addresses, i..e, Uniform Resource Locator (URL). In this way, any particular entity has a precise identification across multiple information systems. A first relevant consequence of this is that if multiple parties wish to refer to the same entity in their datasets, e.g., the same person, they simply need to agree on a common URI. For instance, it is becoming common to use VIAF’s identifiers for notable persons, e.g., http://viaf.org/viaf/80351209 for Beethoven, or (when they exist) for artworks, e.g., http://viaf.org/viaf/179828695 for Beethoven’s Ninth Symphony. For instance, the graph in Fig. 3 could be rewritten as the one shown below in Fig. 5, where the use of VIAF’s identifiers is now explicit.

Figure 5 – Use of VIAF’s identifiers
A second interesting consequence concerning the role of URIs is that when different RDF graphs use the same URIs, if they are put together, a node from a graph is easily merged with a node from another graph, which eases data integration. For instance, consider the RDF graph in Fig. 6 representing the very first performance of the Ninth at Theater am Kärntnertor in Vienna on May 7, 1824. By merging it with the graph in Fig. 5 one obtains the larger graph shown in Fig. 7 where, since both graphs use the VIAF’s identifier for the Ninth, the representation of the Symphony is enhanced with further data.
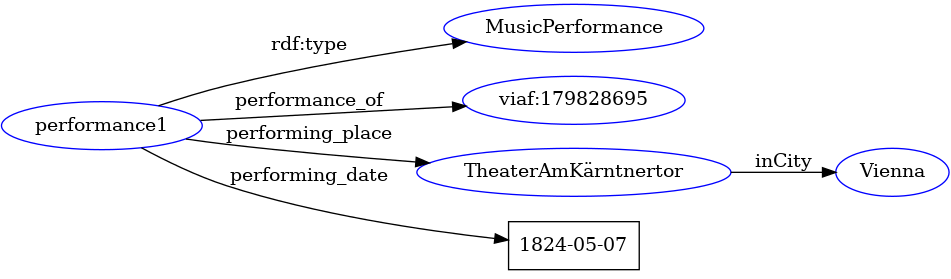
Figure 6 – Performance of the Ninth at Theater am Kärntnertor in Vienna on May 7, 1824
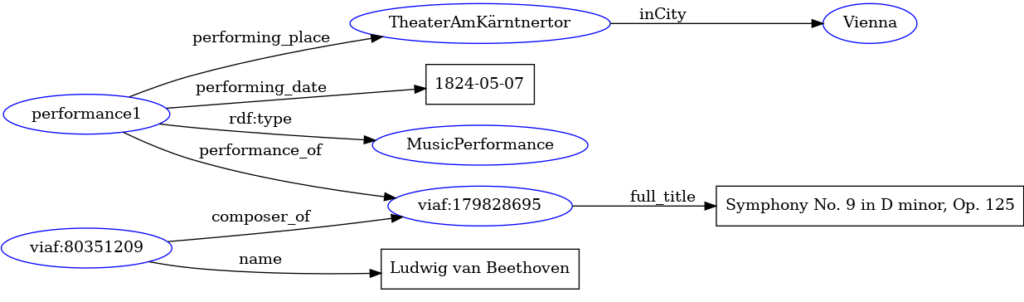
Figure 7– The graphs represented Figures 5 and 6 now merged
Providing a thorough introduction to the Semantic Web is out of our scope here (but see Allemang and Hendler 2011, Hitzler et al 2009, and Hitzler 2021). It is however fundamental to stress that the triples leading to the graphs above are only data-level representations; the graphs are not ontologies because they represent specific individuals, and not their corresponding classes. For instance, in Fig. 5 – as humans – we assume that viaf:80351209 refers to a person and, more specifically, a composer but nothing in the graph makes this information explicit. Here comes what is perhaps the most challenging aspect of ontology design. In fact, apart from technical considerations on how to use formal languages, one needs to draw the classes and relations for the ontology and needs to specify their meanings in a way that reflects shared scholarly knowledge. In some cases this may not be particularly difficult. For instance, we all share the view that a composer is a person who has authored some musical works. Many other modeling cases are more challenging. Consider, for instance, Franz Liszt’s arrangement of Beethoven’s Ninth for solo piano. How many musical works should we include in our information system?
- One – possibly meaning that Beethoven’s Ninth and Liszt’s arrangement are the same musical work despite the variations in the performing forces,
- Two – possibly because Beethoven’s Ninth and Listz’s arrangement are two different interrelated works.
More generally, what is a musical work, namely, what does characterize their nature and how do we distinguish between different (possibly interrelated) works? Is the identity of musical works bound to their production contexts and authorial performing forces? Is it possible to change the performing forces of a musical work while retaining its identity? The answers might seem to those familiar with the European tradition of concert music self-evident (that Liszt’s arrangement is still Beethoven’s work). But there are of course traditions that would understand different renditions (say, of a raga, or of a folktale) as to separate utterances, not realizations of some singular work.
These are the sorts of questions we need to ask when developing ontologies. There are not easy ways of dealing with them and ontologists have to provide solutions that, on the one hand, fit scholars’ knowledge, and on the other hand satisfy the requirements for which an ontology is developed. This inevitably leads to simplifications. It is however a common practice in Applied Ontology to make conceptual analyses – on the grounds of domain-specific knowledge (e.g., musicology) and philosophy – to properly capture experts’ knowledge. In this way, a pragmatic solution can be identified while being aware of the complexity of scholars’ knowledge (Keet 2018).
OMAC – Ontology for Analytic Musical Claims
In the context of CRIM, we need to represent at least two main kinds of entities, namely, musical works and musicological claims about them. The world of music is full of many other kinds of things, e.g., scores, performances, orchestras, composition events, etc. which we leave out of this first release of OMAC, although the ontology could be extended to cover these bits of information, too. In particular, once developed, we would like OMAC be able to retrieve (via queries) data of the sort:
- Who is the composer of a musical work?
- Which authorial parts (movements, sections) does a musical work have (if any)?
- What is the genre of a musical work? (A more specific query asking for genre could be: What are the musical works with genre mass?)
- Who is the author of a musicological claim (observation)?
- To which work (or works) does a given claim refer?
- What portions of the work does the claim refer to? These fragments are of course part of the composition, but they are not strictly speaking the same as authorial parts (see below for more discussion).
- What kinds of insights does the claim make? In the case of CRIM, analysts assert that a given fragment of work is an instance of some structural pattern or schema, like a cadence?
We could also imagine other kinds of claims, such as one that asserts the authorship or date of a given composition, or offers some statement about the meaning or value it carries in a cultural context. But most importantly for CRIM we need to model the idea of similarity:
- How are two works connected with each other through some shared pattern? Here our OMAC model thus needs to connect two pieces (a model and a derivative) as a similarity relationship.
Formalizing this kind of project-level information can be challenging. But it helps in making CRIM data FAIR, and it also serves to give clear attribution (and credit) to the kinds of otherwise invisible intellectual labor that goes into collaborative projects. In this sense OMAC points to something that is FAIR+ (adding Responsible to the familiar attributes of Findable, Accessible Interoperable, and Reusable). At the end of this essay, we will show how data relative to (some of) these queries can be retrieved.
Here we take a single CRIM Observation (https://crimproject.org/observations/622/, see Figure 8) as a case in point. What does the human reader find here?
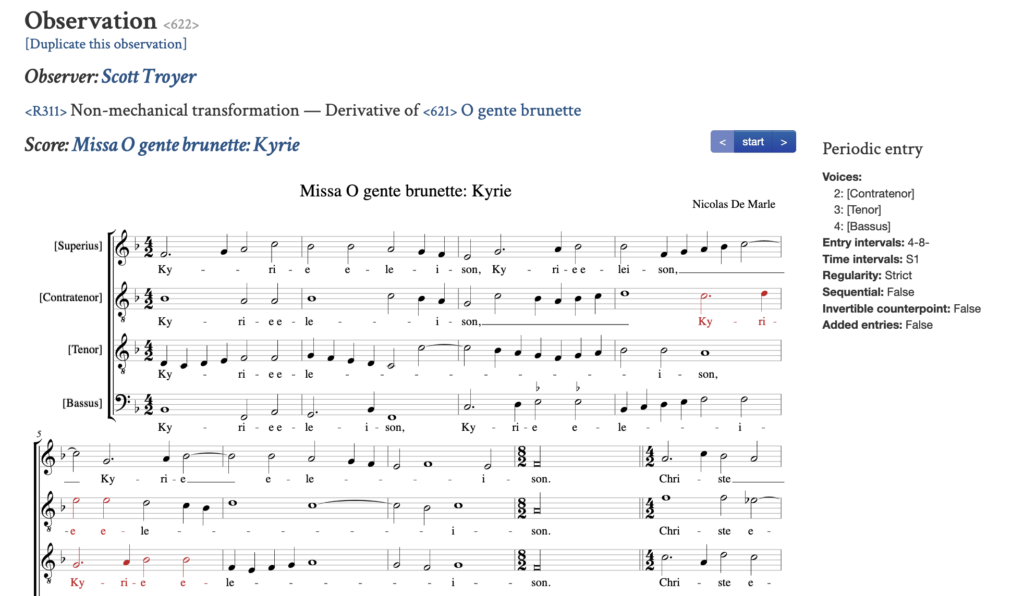
Figure 8. A Single Observation from the CRIM project (https://crimproject.org/observations/622/)
Users of the project will understand that different parts of this page represent the score of a work (in this case a Kyrie from Nicolas De Marle’s Missa O gente brunette), which itself is part of a cycle of movements all based on the same chanson. They will also understand that a CRIM analyst (Scott Troyer) has identified a passage in measures 4 through 6 in which three voices form a very brief series of Periodic Entries. The relevant passage is highlighted with a score annotation, plus additional data about the musical pattern found here–the time intervals between entries and the melodic distance from the first note of one entry to the first note of the next.
The web page also directs the reader to a related passage in the chanson (https://crimproject.org/observations/621/) in which the same melodic idea is presented not as a Periodic Entry but simply as a Contrapuntal Duo. Taken together, the pair of observations forms a relationship (https://crimproject.org/relationships/311/) in which the analyst makes a claim about how these two passages are connected. But how can we represent these ideas in a formal way that is expressible through a Semantic Web ontology? Let’s consider parts of the work and the claim in detail.
Musical works, movements, and sections.
Our model must have a way of showing that the Kyrie (in Troyer’s observation) is one of five movements of the work we call the Mass. And it would be useful to show that the Kyrie itself has three sections (Kyrie I, Christe, and Kyrie II) planned by De Marle as he followed the traditional tripartite division of this portion of the Mass text. Of course humans understand intuitively that Kyrie I is part of the Mass (no less than it is a part of the Kyrie). But unless we make this explicit in our ontology, a machine can not infer this fact.
In the diagram presented in Figure 9, we show the division of a whole work into sections (movements) and subsections as given by composers and identified in scores through, e.g., formal divisions. The system used here follows the UML Class Diagram notation, a modeling language broadly used in conceptual modeling and applied ontology to provide an intuitive graphical view of domain elements and their interrelations. Also, its relationships with Semantic Web languages are well-studied (Berardi et al. 2005). On the basis of this model, we can now provide a formal representation of the Mass o gente brunette with all its authorial sections and subsections, see Fig. 10.
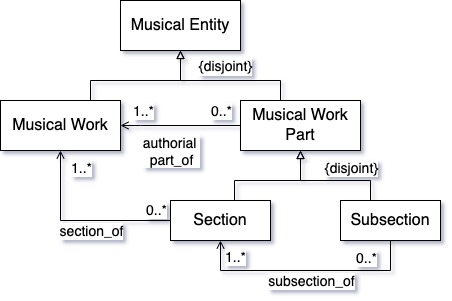
Figure 9 – The authorial division of musical works
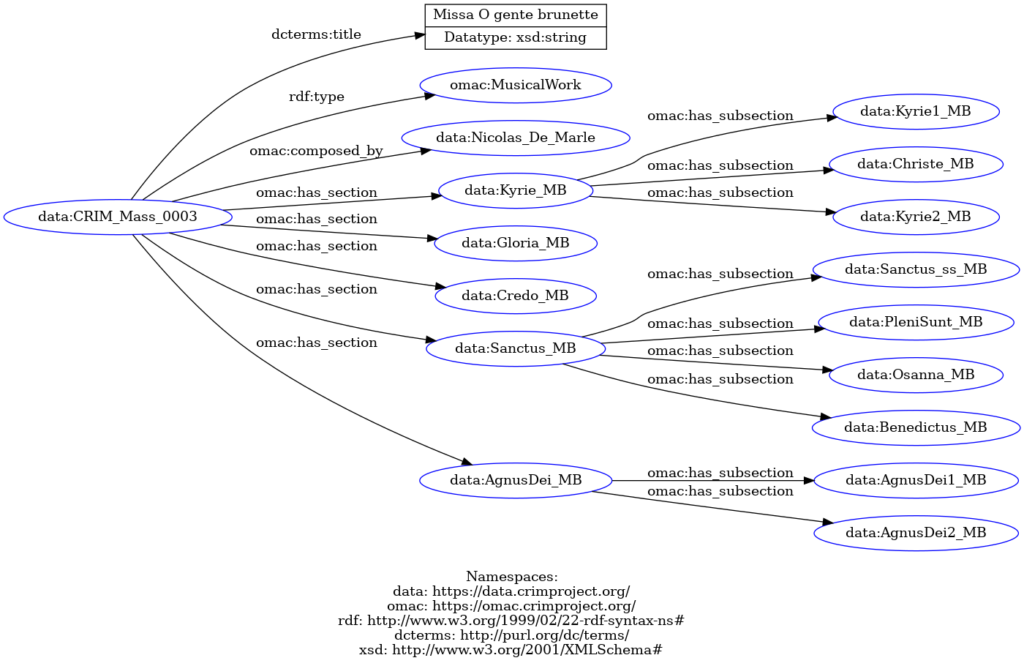
Figure 10 – Decomposition of the authorial structure of the Missa O gente brunette
We can enrich this structure still further. Besides the representation of the basic authorial parts of a work , OMAC also allows us to make explicit other aspects of a given composition, such as genre, performing forces, composition date, and so on.
Scholarly claims (aka observations). We now need to introduce further modeling elements in order to represent scholarly claims of the sort that Scott Troyer makes in CRIM Observation 622.
Recall that in the case of musicology, debates about date, or even authorship of works from the years before 1600 are common, and entirely understandable given the sparse documentary record about the specific occasions that led to the creation of a particular work. Surprisingly few works from the period survive in copies associated directly with their composers. Thus even basic statements about a piece might better be modeled as contingent observations rather than given facts.
The situation is even more complex (and hotly debated) in the case of analytic, structural, or stylistic assertions about a musical work. Scholars might well want to claim that a particular work is beautiful, or that a particular part in the work represents something remarkable. Such claims are typical in the world of analysis and criticism, yet they lack any well-established and shared vocabulary by which they can be made accessible to any beyond those who take the time to read complex narrative arguments or analytic charts. A vast analytic database of thousands of analytic observations compiled in the course of the CRIM project nevertheless provides a good testing ground for ways to model such critical claims.
From the ontology modeling perspective, we found it useful to build our approach on the framework proposed by Masolo et al. (Masolo et al. 2018), which has already been applied to document scholarly observations in literary criticism (Sanfilippo et al. 2023). In their proposal, the authors introduce a general notion of observation to represent the classification of entities under (relational) properties as result of analytic, cognitive or empirical procedures, among others, of different sorts. In a sense, when an observation attributes the authorship of a composition to a certain person, it means that – according to the results of scholarly investigation – the person bears that role, although this information may not match how the world is, it is just an (scholarly) hypothesis. In addition, it is also possible to have incompatible observations about the same entities; e.g., as we will see with respect to CRIM, different scholars may attribute different musical schemas to the same analytic segments. To make the proposal concrete from a modeling standpoint, Masolo et al.’s (2018) framework consists in the introduction of controlled observational vocabularies reflecting how observations are expressed in specific application domains such as musicology, literature, history of arts, and so on. Hence, each term in a vocabulary stands for a kind of observation, namely, it collects individual observations classifying entities in a similar manner (see below for examples). The overall approach of Masolo and colleagues is more complex than what just said, although, for the sake of the presentation, this short introduction suffices.
In our work on CRIM and OMAC, we have distinguished between two principal observation kinds, namely, observations of structure and observation of similarity. Figure 8, above, for instance, is a claim about a particular kind of structural feature that analyst Scott Troyer found in a particular composition. But in the CRIM Project we also need to take note of the ways in which two such passages might be “similar” (on account of borrowing or more general stylistic norms). Let’s look at these two kinds of claims in detail, and how they are modeled in OMAC.
A Claim about Structure. A CRIM observation about structure says something about a structural pattern in some work. An analyst (Troyer in this case) identifies a fragment of a work (or more precisely, a fragment of an authorial section of a work, like the Kyrie). The analyst then attributes to this segment (as we call the selected portion the score) a musical schema (e.g., fuga, cadence, soggetto, etc.), the latter being introduced in our controlled vocabulary of musical types (as shown in Fig. 8 in the previous section).
In order to make these observational data available in OMAC, we include in the ontology modeling elements to represent things such as analytic segments, observers, (different sorts of) observations, etc. Figure 11 shows the modeling pattern for the representation of structure claims. In particular, instances of (the class) Structure Observation concern analytic segments to which they assign specific attribute values.
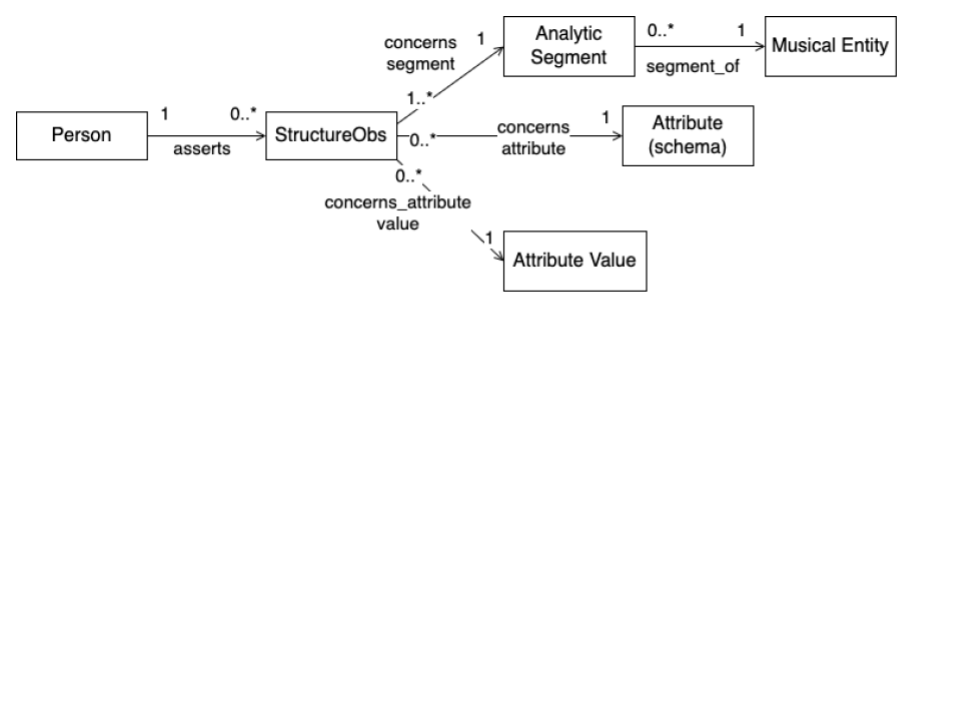
Figure 11 – Modeling pattern for Structure Claim
The RDF graph in Fig.12 (partially) represents Troyer’s structure observation through the pattern in Fig. 11. The observation (data:obsStr622) is the main datum, which in turn is linked to the person who created it (data:Scott_Troyer), the segment, and the attributed schema (each analytic segment is uniquely identified through an EMA reference in the CRIM database; for the sake of shortness we use only the placeholder ’ema’ instead of its full identifier).
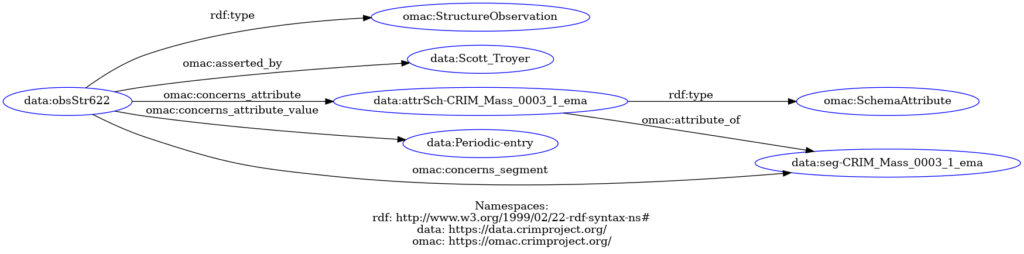
Figure 12 – Structure Claim by Scott Troyer in RDF according to OMAC
Claims about Similarity. These kinds of observations in CRIM identify the similarity between two musical entities, one considered as model and the other one as derivative. For example, according to Troyer (https://crimproject.org/relationships/311/), there is a similarity relationship of kind non-mechanical transformation holding between (a segment of) Thomas Champion’s O gente brunette (the model) and (a segment of) Nicolas de Marle Kyrie of the Missa O gente brunette (the derivative).
As for the case of structure observations, the vocabulary for (different types of) musical relationships of similarity has been identified by music scholars in the project and this has been used to extend OMAC with the necessary modeling elements (see Fig. 13).
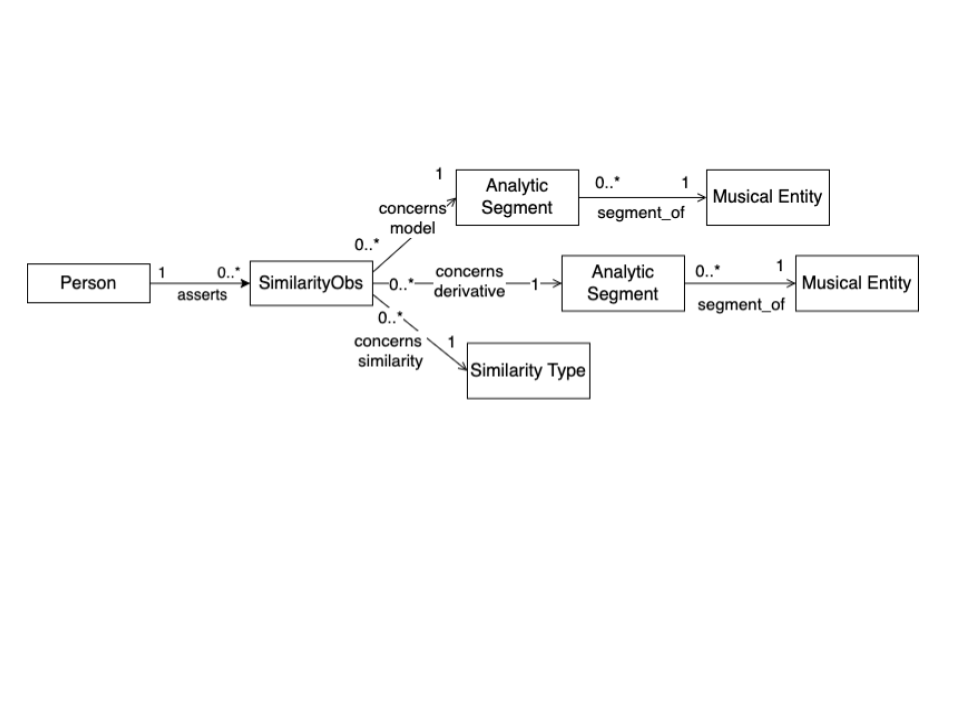
Figure 13 – Modeling pattern in OMAC for Similarity Claim
Following our example, the RDF graph in Fig. 14 shows the representation of the similarity between a segment of Champion’s O gente brunette and a segment of the Kyrie section of the Missa O gente brunette by de Marle. To comment on the graph, the relations omac:concerns_derivative and omac:concenrs_model are used to link an observation of similarity to the musical entities it concerns, whereas omac:concerns_similarity is used to qualify the similarity type attributed to by the analyst.

Figure 14 – Similarity Claim by Scott Troyer in RDF according to OMAC
We show in the next section how OMAC is used in a prototype application to access some portions of the CRIM’s data making it available in RDF.
Towards a LOD application to explore CRIM data
There exist different techniques to exploit Semantic Web models. Since CRIM relies on a relational database, we adopt an Ontology-based Data Access (OBDA) approach by using the OnTop (Calvanese et al. 2017) knowledge graph system (see also https://ontop-vkg.org/). OBDA approaches allow to combine relational data structures with Semantic Web technologies by taking the benefits of both approaches. In particular, in terms of OBDA, it is not necessary to duplicate the data in a new format, as one would do if the data were extracted from the source database, translated in RDF, and fed into a RDF triplestore.
Without digging into the technical aspects, the general idea of OBDA is to state mappings between a target ontology, OMAC in our case, and the schema of a source relational database, the CRIM database for us. A mapping is a formal expression telling an OBDA engine how to rewrite relational data as RDF triples according to the vocabulary and structure of the selected ontology. In this manner, the ontology and the mappings expose a virtual RDF graph of the data, which can be queried using SPARQL, the query language for the Semantic Web. A virtual RDF graph can be materialized to generate RDF triples to be used with RDF triplestores; otherwise, the graph can be used only in virtual mode and accessed during query execution (see Calvanese et al. 2017).
As said, we rely on the OnTop system. OnTop is developed at the Free University of Bozen-Bolzano (Italy), is open source, supports all the W3C recommendations related to OBDA, and has a plugin for Protégé (a widely used software for ontology development in OWL; https://protege.stanford.edu/). In addition, OnTop has a SPARQL endpoint to query a virtual RDF graph.
To present an example, let us consider an OBDA mapping for some elements in the CRIM database. Table 1 shows an excerpt of data from the crim_crimmass table in the database. In particular, for each mass, this partial view of the table provides the id, title, and id of the composer.
| mass_id | title | composer_id |
| CRIM_Mass_0005 | Missa Ave Maria | CRIM_Person_0015 |
| CRIM_Mass_0009 | Missa tota pulchra es | CRIM_Person_0021 |
Table 1 – Excerpt of data from the CRIM database, crim_crimmass table
As we have seen in the previous sections, a mass in the OMAC ontology is an instance of the class Musical Work; reference to titles can be done through the (data property) Dublin Core relation named title, whereas the native OMAC’s (object property) relation composed_by can be used to link a musical work to its composer. Also, recall that OMAC allows for the further characterization of musical works, e.g., by adding their genre, composition dates, etc.
An OBDA mapping assertion consists of two parts: a source, i.e., a SQL query retrieving values from the relational database, and a target to define RDF triples with values from the source. In the example in Fig. 15 mass_id, title, and composer_id in the source are values from the database that are used in the target to populate the ontology (for the sake of the example, this is only a simplified version of the mapping).

Figure 15 – Example of OBDA mapping from the crim_crimmass table to RDF through OMAC
Once the mapping has been stated, we can run a SPARQL query to retrieve the data. This can be done through the query in Fig. 16 (this is only a simplified version of the query; e.g., we omit the declaration of prefixes):

Figure 16 – Example of SPARQL query
The query leads to results like the following ones, showing now data in the form of RDF triples which, as said, can be materialized and stored in a triplestore, if needed.
| ?work | ?massTitle | ?massComposer |
| :me-CRIM_Mass_0005 | “Missa Ave Maria” | :person-CRIM_Person_0015 |
| :me-CRIM_Mass_0009 | “Missa tota pulchra es” | :person-CRIM_Person_0021 |
Table 2 – Some results for the SPARQL query above over the virtual RDF graph of CRIM
By means of OnTop we have implemented an OBDA-based SPARQL endpoint to access portions of the CRIM data through OMAC. The endpoint is available at: https://lod.crimproject.org/ (see Figure 17 and Figure 18 for an example of SPARQL query and some results retrieved through the SPARQL endpoint). As noted in the previous sections, making the CRIM data available in Semantic Web languages is a first fundamental step to make them FAIR(eR) within and outside the scope of the project. In addition, we can now employ inference mechanisms to automatically reason over data through the formal structure of the ontology. Hence, we can express queries over the database that take advantage of inference results.
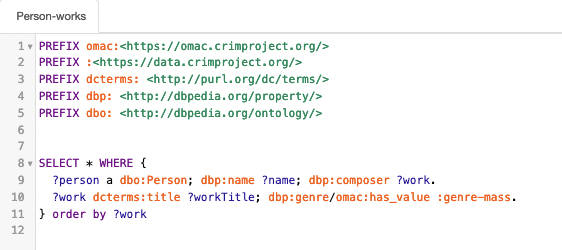
Figure 17 – Example of SPARQL query
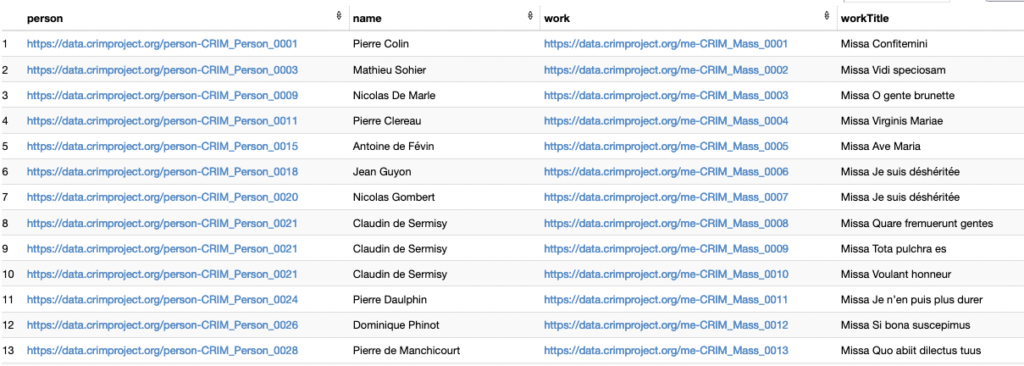
Figure 18 – Some results for query in Fig. 17
Acknowledgment
We wish to thank Francesco Corcoglioniti and Alessandro Mosca (Free University of Bozen-Bolzano, Italy) for their valuable suggestions on the use of OnTop, as well as Daniel Russo-Batterham (University of Melbourne, Australia) and the technical team of CRIM for their support. We also wish to thank colleagues at the CESR University of Tours (France), and at the ISTC-CNR Laboratory for Applied Ontology (Italy) for the several discussions that helped in shaping the ideas behind OMAC.
This essay is partially based on Sanfilippo, E. M., & Freedman, R. 2022. “Ontology for Analytic Claims in Music.” In New Trends in Database and Information Systems: ADBIS 2022 Short Papers, Doctoral Consortium and Workshops: DOING, K-GALS, MADEISD, MegaData, SWODCH, Turin, Italy, September 5–8, 2022, Proceedings, pp. 559-571. Cham: Springer International Publishing.
References
Allemang, Dean, and James Hendler. Semantic Web for the Working Ontologist: Effective Modeling in RDFS and OWL. Elsevier, 2011.
Barabucci, Gioele, Francesca Tomasi, and Fabio Vitali. 2021. “Supporting complexity and conjectures in cultural heritage descriptions.” In Collect and Connect: Archives and Collections in a Digital Age 2020, Proceedings of the International Conference Collect and Connect: Archives and Collections in a Digital Age (COLCO 2020), Leiden, the Netherlands, November 23-24, 2020, edited by Andreas Weber, Maarten Heerlien, Eulàlia Gassó Miracle, Katherine Wolstencroft, pp. 104-115. Aachen: CEUR-WS. https://ceur-ws.org/Vol-2810/paper9.pdf
Berardi, Daniela, Diego Calvanese, and Giuseppe De Giacomo. 2005. “Reasoning on UML class diagrams.” Artificial intelligence 168, no. 1-2: 70-118.
Berners-Lee, Tim, James Hendler, and Ora Lassila. 2001. “The Semantic Web.” Scientific American 284, no. 5: 34-43.
Berto, Francesco, and Matteo Plebani. 2015. Ontology and Metaontology: A Contemporary Guide. Bloomsbury Publishing.
Calvanese, Diego, Benjamin Cogrel, Sarah Komla-Ebri, Roman Kontchakov, Davide Lanti, Martin Rezk, Mariano Rodriguez-Muro, and Guohui Xiao. 2017. “Ontop: Answering SPARQL queries over relational databases.” Semantic Web 8, no. 3: 471-487.
Freedman, Richard, editor. 2022. CRIM Vocabulary of Musical Types. Haverford, PA: The CRIM Project. https://sites.google.com/haverford.edu/crim-project/vocabularies/musical-types?authuser=0&pli=1
Freedman, Richard, editor. 2022. CRIM Vocabulary of Relationship Types. Haverford, PA: The CRIM Project. https://sites.google.com/haverford.edu/crim-project/vocabularies/relationship-types.
Giunchiglia, Fausto, and Ilya Zaihrayeu. 2007. “Lightweight ontologies.” http://eprints.biblio.unitn.it/1289/
Goehr, Lydia. 1992. The Imaginary Museum of Musical Works: An Essay in the Philosophy of Music. Oxford: Clarendon Press.
Guarino, Nicola, Daniel Oberle, and Steffen Staab. 2010. “What is an Ontology?” In Handbook on Ontologies, edited by Steffen Staab and Rudi Studer, pp. 1-17. Berlin: Springer.
Guarino, Nicola and Mark Musen. 2015. “Applied ontology: The Next Decade Begins”. Applied Ontology, 10(1): 1-4.
Hitzler, Pascal, Markus Krotzsch, and Sebastian Rudolph. 2009. Foundations of Semantic Web Technologies. New York: Chapman and Hall/CRC.
Hitzler, Pascal. 2021. “A Review of the Semantic Web Field.” Communications of the ACM, 64(2): 76-83.
Keet, Maria. 2018. An Introduction to Ontology Engineering. Vol. 1. Cape Town, South Africa: Maria Keet, 2018.
Masolo, Claudio, Alessander Botti Benevides, and Daniele Porello. 2018. “The Interplay Between Models and Observations.” Applied Ontology 13, no. 1: 41-71.
Pietras, Monika, & Robinson, Lyn. 2012. “Three Views of the ‘Musical Work’: Bibliographical Control in the Music Domain.” Library Review, 61(8/9): 551-560.
Sanfilippo, Emilio M., Sotgiu, Antonio, Tomazzoli, Gaia, Masolo, Claudio, Porello, Daniele, Ferrario, Roberta forthcoming 2023. “Ontological Modeling of Scholarly Statements: A Case Study in Literary Criticism.” In: Proceedings of FOIS 2023. IOS Press
Smiraglia, Richard. 2001. “Musical Works as Information Retrieval Entities: Epistemological Perspectives.” In ISMIR (pp. 85-91).
Staab, Steffen and Rudi Studer, editors. 2010. Handbook on Ontologies. Springer Science & Business Media.
Wilkinson, Mark D., Dumontier, Michael, Aalbersberg, IJsbrand Jan, Appleton, Gabrielle, Axton, Myles, Baak, Arie., … & Mons, Barend. 2016. “The FAIR Guiding Principles for Scientific Data Management and Stewardship.” Scientific Data, 3(1): 1-9.